Summary of everything we know about GLM-4.7 so far
I’ve been seeing some discussion about Zhipu AI’s new model, GLM-4.7, which dropped yesterday. Since it’s often hard to parse the marketing fluff from the actual technical details, I went through the documentation and early reports to break down what this model actually does and where it sits in the current lineup.
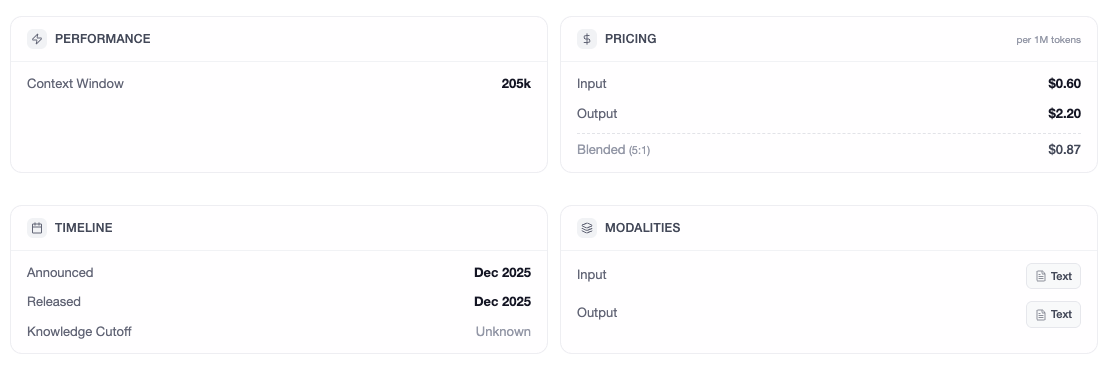
Here is the breakdown of the specs, performance, and pricing.
The Technical Specs
The model is built on a Mixture-of-Experts (MoE) architecture. Zhipu seems to be focusing on efficiency here—activating specific "experts" for tokens rather than the whole model, which is the standard trend for recent frontier models to keep inference costs down.
* Context Window: 200,000 tokens.
* Max Output: 128,000 tokens.
* Modality: Text-in, Text-out. (If you need vision, you still have to use their GLM-4v variants).
Coding Capabilities
The strongest claims for this model revolve around programming. It’s not just about generating snippets; the focus is on "agentic" coding - basically handling full task completion, requirement decomposition, and multi-file integration.
I found the "vibe coding" aspect interesting. The documentation notes that they specifically optimized the model for aesthetic output. When generating UIs (webpages, slides, frontend components), it supposedly defaults to cleaner, more modern layouts rather than the generic, broken-looking templates we usually get from LLMs. You can test this yourself through the Website arena that we have and adding this to the list of models.
The Coding Benchmarks:
> * SWE-bench: 73.8% (+5.8% over GLM-4.6). This measures capability on real GitHub issues, not just LeetCode problems.
> * SWE-bench Multilingual: 66.7%.
> * Terminal Bench: 41% (handling command line interactions).
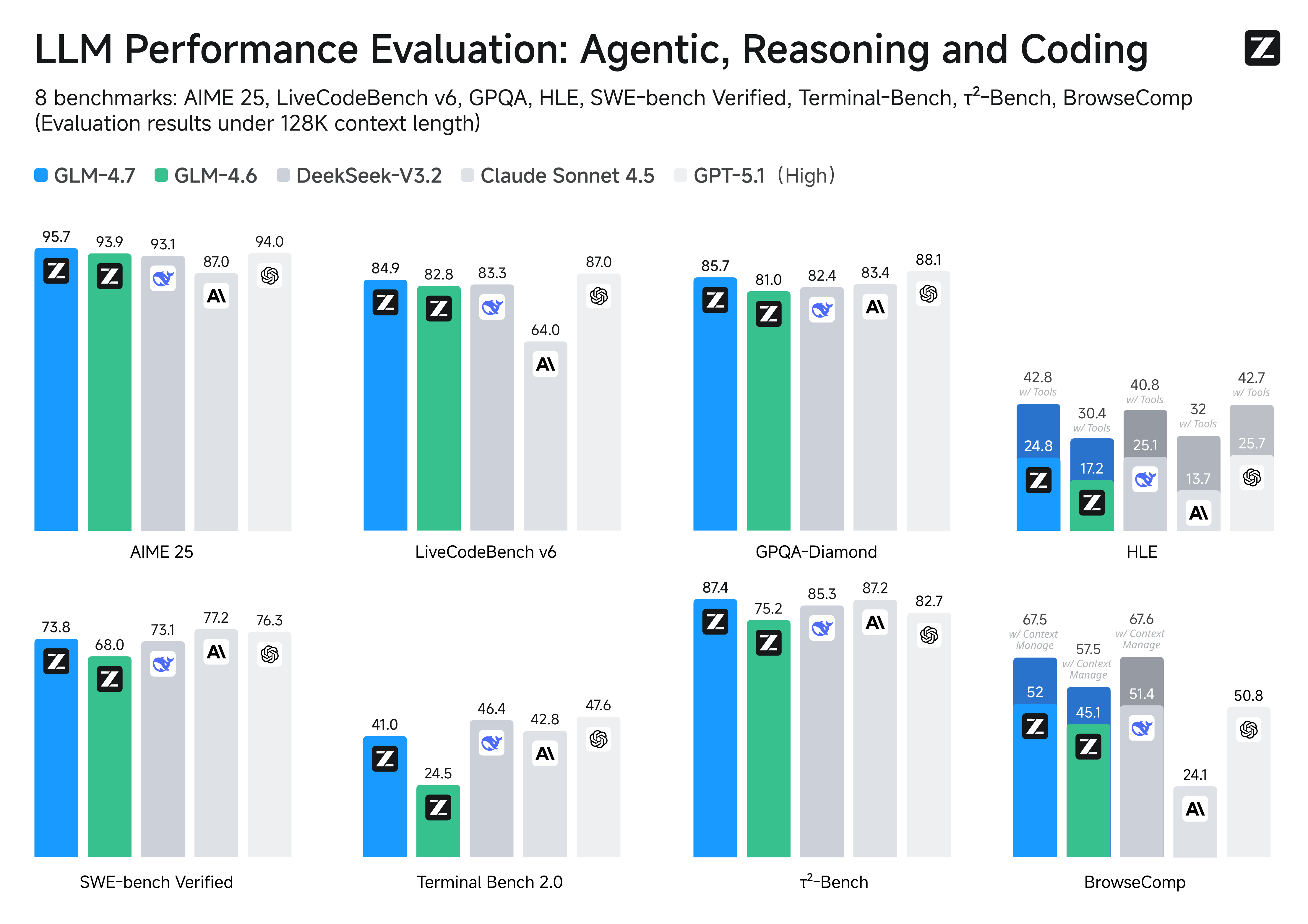
Reasoning and "Deep Thinking"
They have implemented a "Deep Thinking" mode, similar to what we've seen with o1-style models. When you enable thinking={ type: "enabled" } in the API, the model explicitly reasons through the problem before answering.
On the Humanity's Last Exam (HLE) benchmark, which is designed to be much harder than standard academic tests, it scored 42.8%. That might sound low, but it's actually a +12.4% jump over the previous version, putting it in competitive territory for complex reasoning tasks.
Tool Use and Streaming
For developers building agents, the tool-use updates are relevant. It hit top-tier results on [τ²-Bench](https://github.com/sierra-research/tau2-bench) (a complex multi-step tool benchmark).
A nice quality-of-life feature they added is tool_stream=true. This allows you to stream the parameters of a tool call as they are being generated, rather than waiting for the model to finish constructing the whole JSON object. If you are building latency-sensitive voice or chat apps, this cuts down the wait time significantly.
Pricing
The pricing is competitive, specifically regarding caching.
* Input: $0.60 / 1M tokens
* Output: $2.20 / 1M tokens
* Cached Input: $0.11 / 1M tokens
The cache pricing is the standout here. If you are running agents that reuse heavy system prompts or documents, the drop to $0.11 makes it very cheap to run.
TL;DR
GLM-4.7 is a text-focused MoE model with a massive 128k output limit. It explicitly targets "agentic" workflows with strong tool-use performance and specific optimizations for writing better-looking frontend code. It's cheap to run if you utilize prompt caching.
Try it out through our playground today: https://llm-stats.com/playground