Everything we know about GLM-4.7 Flash so far (Architecture, Reasoning, and Benchmarks)
I've been seeing a lot of discussion about Z.AI’s new GLM-4.7 Flash lately, specifically regarding its performance-to-size ratio. Since there is often confusion about where these open-weight models fit in the stack compared to proprietary giants, I dug into the technical report and documentation to break down exactly what this model is and why it matters for developers.
Here is a summary of the architecture, the new "thinking" mechanics, and how it runs locally.
The Specs: Efficient 30B MoE
The headline here is that GLM-4.7 Flash isn't a standard dense model; it uses a Mixture-of-Experts (MoE) architecture. While the total parameter count is 30 billion, the sparse activation means it only uses a fraction of those parameters per token. This allows it to punch above its weight class while keeping inference costs (and latency) manageable.
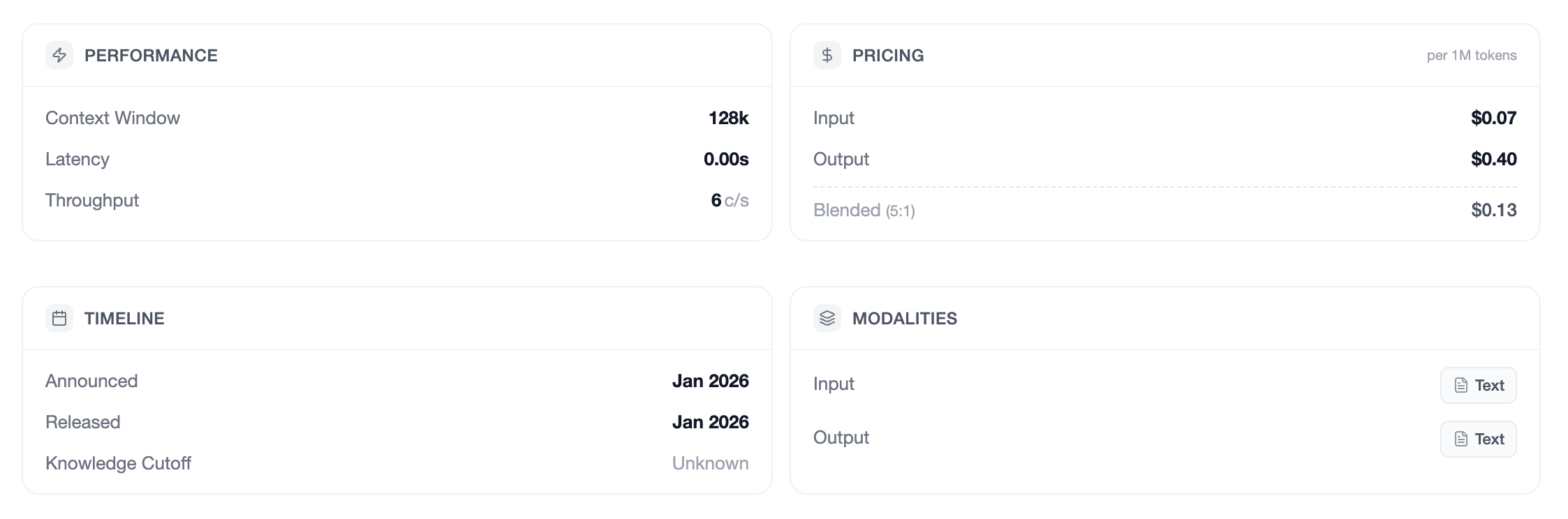
- Context Window: It supports a ~128k token context window.
- Output Capacity: It can generate up to 128k tokens in specific configs, though practically you're usually looking at 16k-40k for standard coding tasks.
- Positioning: It sits as the lightweight alternative to the massive 355B GLM-4.7, designed specifically to run on mid-range enterprise or high-end consumer hardware.
"Interleaved Thinking" and Reasoning
This is the part I found most interesting from a technical perspective. Most models do their Chain of Thought (CoT) in one block at the start. GLM-4.7 Flash uses Interleaved Thinking.
* Step-by-Step Action: Instead of planning everything upfront, the model reasons sequentially before each tool call or action. This is huge for agentic workflows where the model needs to see the result of a terminal command before deciding the next step.
* Preserved Thinking: If you are in a multi-turn conversation (like debugging a complex error), the model maintains its internal reasoning scaffolding across messages. It doesn't "forget" why it made an architectural decision three turns ago.
* Control: You can actually toggle this. If you just want a quick regex fix, you can disable the thinking capability to save tokens/time. For complex architecture, you leave it on.
Coding and "Vibe Coding"
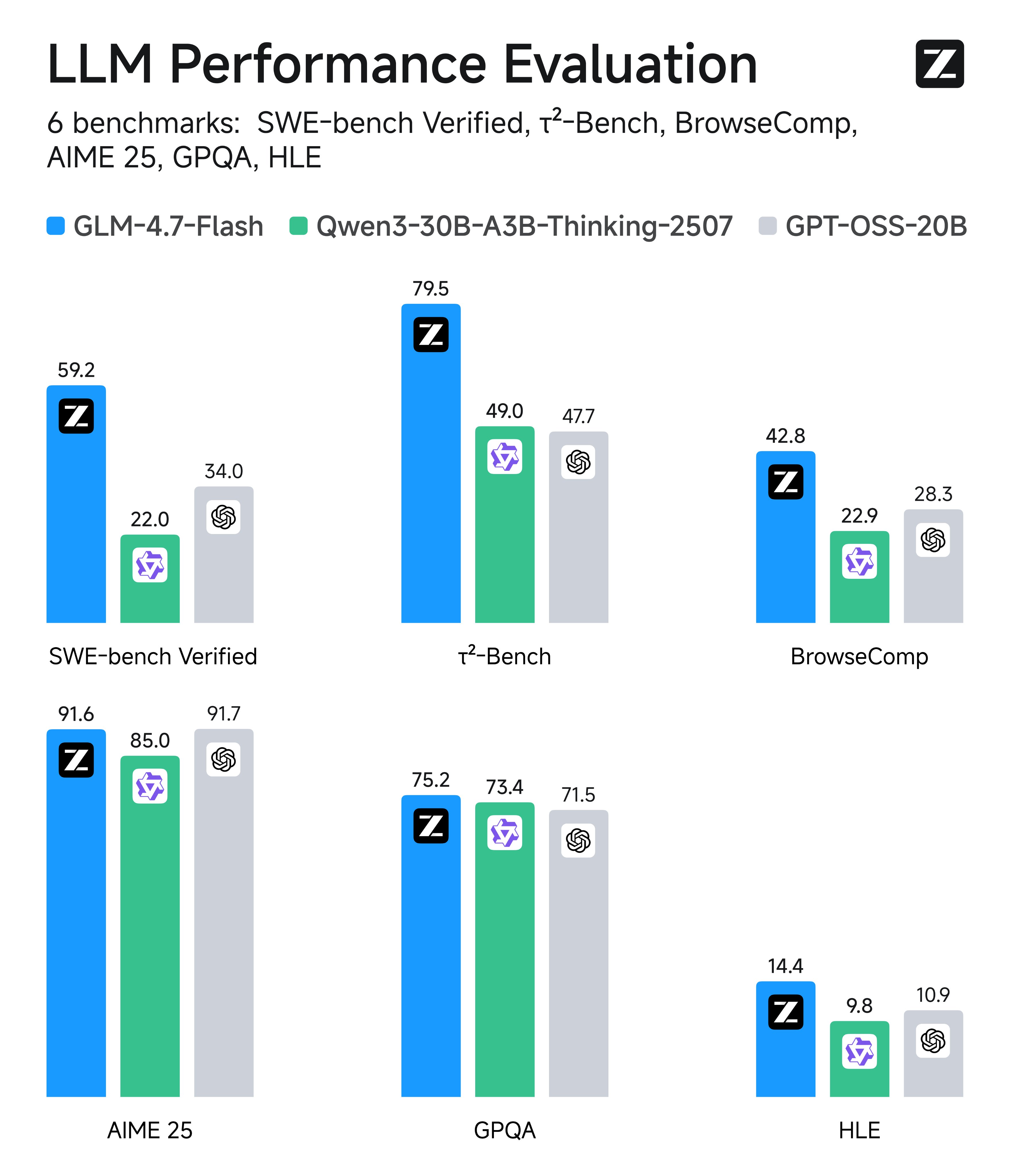
The benchmarks (SWE-bench Verified and tau2-bench) claim it hits state-of-the-art for the 30B class, specifically in repository-level understanding rather than just snippet generation.
One specific capability mentioned in the docs is the widely known term "Vibe Coding". Essentially, the model has been fine-tuned to have a better grasp of frontend aesthetics. Instead of generating technically correct but bad HTML/CSS, it leans toward modern design patterns, correct whitespace usage, and harmonized color schemes.
It also seems to excel at Terminal/CLI workflows. It understands package management, permission models, and file system navigation better than generic text models, likely due to specific training on DevOps and infrastructure-as-code datasets.
Running it Locally vs. API
Because this is an open-weight release, you aren't forced to use their API.
* Hardware Requirements: A 30B model is heavy for a standard gaming PC, but because of the MoE architecture and quantization, it's accessible.
* Quantization: There are 4-bit and 2-bit quantized versions available. Using Unsloth's dynamic quantization, you can squeeze this into environments that usually wouldn't handle a 30B model (like high-VRAM consumer GPUs with some CPU offloading).
* API: If you don't have the hardware, the API pricing is aggressive (~$0.60/1M input tokens), positioning it as a cheaper alternative to things like GPT-4o-mini or Claude Haiku while aiming for better reasoning performance.

Practical Use Cases
Based on the specs, this model fits into a specific niche:
1. Local Coding Agents: If you are building a VS Code extension or a local agent like Cline/Roo Code, this is a strong candidate for the "heavy lifting" model that doesn't cost a fortune.
2. Hybrid Routing: Use a frontier model (Claude 3.5 Sonnet, etc.) for the hardest 10% of prompts, and route the other 90% (boilerplate, refactoring, tests) to GLM-4.7 Flash to cut costs without dropping to low model quality.
3. Data Privacy: Since you can host it, it’s viable for enterprise environments where code cannot leave the VPC.
TL;DR
GLM-4.7 Flash is a 30B parameter MoE model that targets high-end coding performance. It features "interleaved thinking" for better agentic workflows, handles aesthetics well ("vibe coding"), and is open-weight for local hosting or cheap API usage. It's effectively a bridge between lightweight local models and massive proprietary frontier models.
Try it out through our playground today: https://llm-stats.com/playground