Claude Opus 4.5: Complete Guide, Pricing, Context Window, Benchmarks, and API
A comprehensive look at Claude Opus 4.5 - Anthropic's flagship AI model with 80.9% SWE-bench, 200K context window, Memory Tool, pricing at $5/$25 per 1M tokens, and what it means for developers and enterprises.


Anthropic released Claude Opus 4.5 on November 24, 2025. It's their best model yet--and it shows. An 80.9% score on SWE-bench Verified makes it the top-performing AI for coding, ahead of GPT-5.1 Codex Max (77.9%) and Gemini 3 Pro (76.2%).
But the real story isn't just benchmarks. Opus 4.5 introduces persistent memory across sessions, intelligent context management, and a 66% price cut from the previous version. For developers building agents or enterprises processing large documents, this changes the equation.
Key Specs
View Claude Opus 4.5 on LLM Stats ->
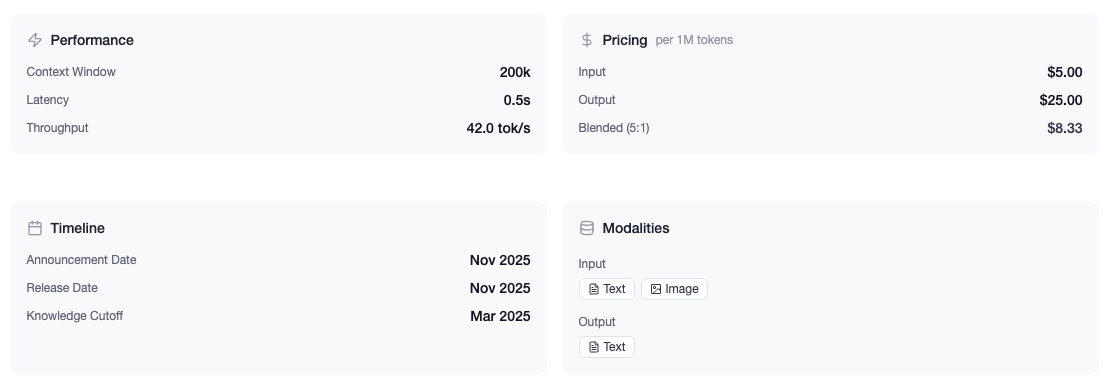
| Spec | Details |
|---|---|
| Release Date | November 24, 2025 |
| Model ID | claude-opus-4-5-20251101 |
| Context Window | 200,000 tokens |
| Input Pricing | $5.00 / 1M tokens |
| Output Pricing | $25.00 / 1M tokens |
| Providers | Claude API, Amazon Bedrock, Google Vertex AI |
The pricing is worth highlighting: Opus 4.1 cost $15 input / $75 output per million tokens. Opus 4.5 drops that to $5 / $25--a 66% reduction while delivering better performance.
What's Actually New
Three features make Opus 4.5 meaningfully different from its predecessor.
Memory Tool
The Memory Tool (currently in beta) lets Claude store and retrieve information beyond the context window. It interacts with a client-side memory directory, which means:
- Claude can build knowledge over time across sessions
- Project state persists between conversations
- You're not constrained by the 200K token limit for long-running work
To enable it:
response = client.beta.messages.create(
betas=["context-management-2025-06-27"],
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[...],
tools=[{"type": "memory_20250818", "name": "memory"}]
)
For agents that need to work on projects over days or weeks, this is significant.
Context Editing
Context Editing (also in beta) automatically manages conversation context as it grows. When you're approaching token limits, it intelligently clears older tool calls while keeping recent, relevant information.
context_management={
"edits": [{
"type": "clear_tool_uses_20250919",
"trigger": {"type": "input_tokens", "value": 500},
"keep": {"type": "tool_uses", "value": 2},
"clear_at_least": {"type": "input_tokens", "value": 100}
}]
}
This is particularly useful for long-running agent sessions where context accumulates over time.
Effort Parameter
The effort parameter lets you trade off between speed and capability:
- Low effort: Fast responses, minimal tokens
- Medium effort: Matches Sonnet 4.5 performance while using 76% fewer tokens
- Maximum effort: Exceeds Sonnet 4.5 by 4.3 points using 48% fewer tokens
This gives you fine-grained control over cost and latency in production.
Benchmarks
View Anthropic's announcement ->
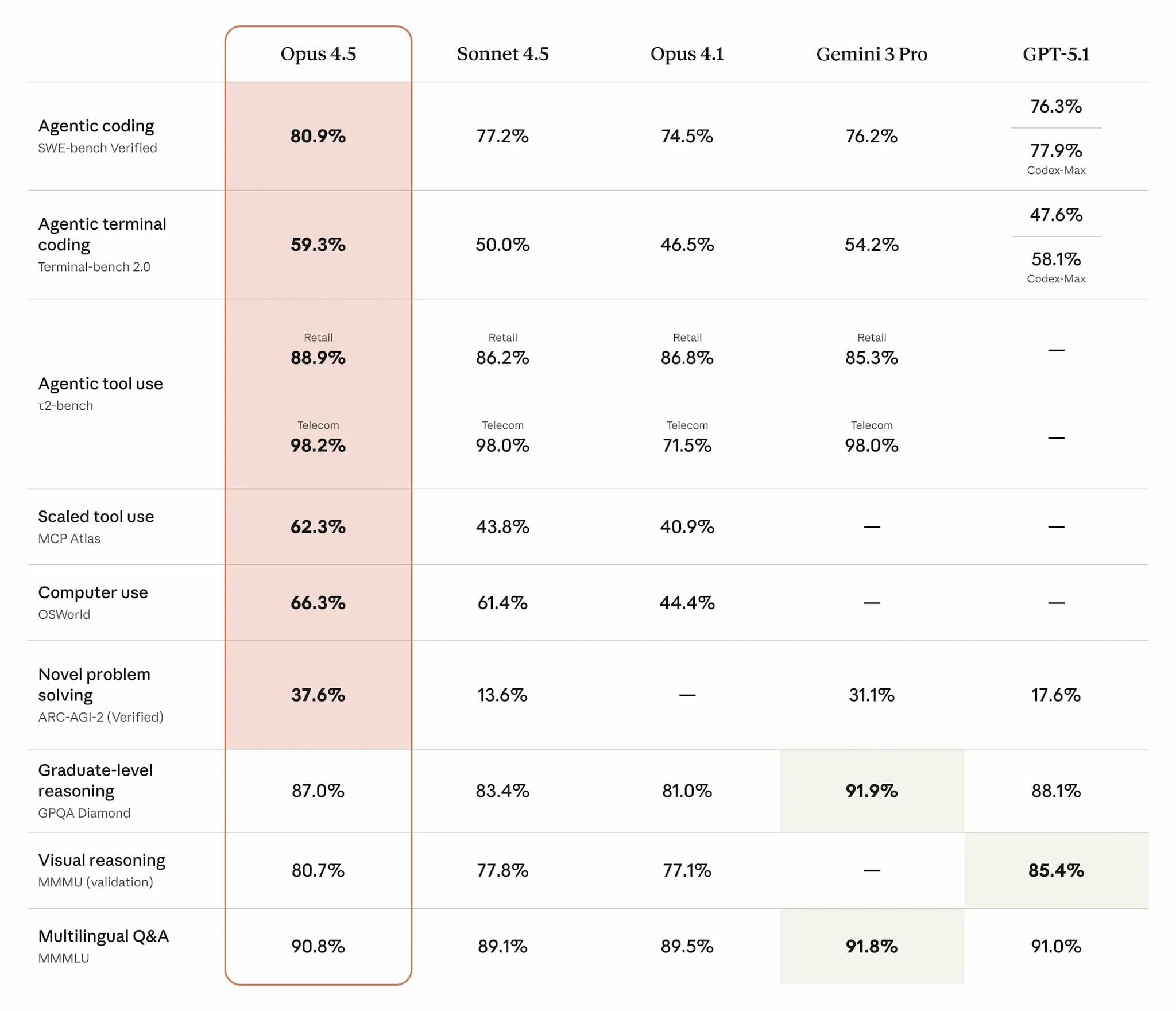
The headline number is SWE-bench Verified at 80.9%--the highest score for any model. This benchmark tests AI on real GitHub issues: understanding codebases, identifying bugs, implementing fixes.
Other notable results:
| Benchmark | Score |
|---|---|
| SWE-bench Verified | 80.9% (#1) |
| Aider Polyglot Coding | 89.4% |
| HumanEval | 84.9% |
| AIME (math reasoning) | 90% |
| GPQA (grad-level problems) | 84% |
| MMLU | 88.3% |
| OSWorld (computer use) | 66.3% |
Opus 4.5 also leads in 7 of 8 languages on SWE-bench Multilingual, showing consistent strength across programming ecosystems.

API Access
Basic usage:
import anthropic
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[
{"role": "user", "content": "Your prompt here"}
]
)
The model is available through:
- Claude API -- Full feature access including beta capabilities
- Amazon Bedrock -- Available since launch with enterprise security controls
- Google Vertex AI -- Generally available
For Memory Tool and Context Editing, add the beta header context-management-2025-06-27 to your requests.
Pricing

| Model | Input (per 1M) | Output (per 1M) |
|---|---|---|
| Opus 4.5 | $5.00 | $25.00 |
| Opus 4.1 | $15.00 | $75.00 |
| Sonnet 4.5 | $3.00 | $15.00 |
Opus 4.5 is still premium-tier pricing, but the 66% reduction from Opus 4.1 makes it more practical for production use. For cost-sensitive applications, the effort parameter helps--medium effort gives you Sonnet-level performance at significantly lower token consumption.
When to Use Opus 4.5
Choose Opus 4.5 for:
- Multi-file refactoring and complex codebase work
- Long-running autonomous agents (Memory Tool is key here)
- Document analysis that benefits from 200K context
- Tasks where accuracy matters more than speed
Consider alternatives when:
- You need sub-second responses -> Haiku 4.5
- High-volume, cost-sensitive workloads -> Sonnet 4.5
- You need 1M+ context -> Gemini 3 Pro
- You want to self-host -> DeepSeek or Llama
Typical latency is 2-4 seconds. For real-time chat or latency-critical applications, Sonnet or Haiku are better choices.
Bottom Line
Claude Opus 4.5 is the best coding model available today by benchmark performance. The Memory Tool and Context Editing features make it genuinely useful for agentic workflows, and the 66% price reduction removes some of the cost barrier.
Whether it's right for you depends on what you're building. For complex coding tasks and autonomous agents, Opus 4.5 is the new default. For everything else, Sonnet 4.5 remains the better value.
Explore the model on LLM Stats or get started with the Claude API.
Questions
Frequently Asked Questions
Claude Opus 4.5 is Anthropic's frontier AI model, featuring state-of-the-art performance on coding benchmarks like SWE-bench Verified and introducing extended thinking for complex multi-step reasoning tasks.
Claude Opus 4.5 outperforms GPT-5 on coding benchmarks (SWE-bench Verified) and safety evaluations, while GPT-5 holds advantages in some mathematical reasoning tasks. See our detailed comparison for benchmark-by-benchmark analysis.
Extended thinking allows Claude Opus 4.5 to reason through complex problems step by step before producing a final answer. This improves accuracy on difficult tasks but increases response time and token usage.
Continue Reading