Gemini 3.1 Pro: Pricing, Context Window, Benchmarks, API & More
A comprehensive guide to Google DeepMind's Gemini 3.1 Pro — the most advanced Pro-tier model as of February 2026, featuring a 1M-token context window, 77.1% on ARC-AGI-2, multimodal reasoning across text, images, audio, video, and code, and access via Gemini API, Vertex AI, and Google Antigravity.


Gemini 3.1 Pro is Google DeepMind's newest flagship model for complex reasoning, long-context understanding, and multimodal work across text, images, audio, video, and code. It builds directly on Gemini 3 Pro and powers Google's consumer, enterprise, and developer products, including the Gemini app, NotebookLM, Vertex AI, and the Gemini API. Gemini 3.1 Pro targets advanced use cases like agentic workflows, algorithm design, large-scale data synthesis, and sophisticated coding rather than casual chat.
In this guide, you will get a practical overview of Gemini 3.1 Pro pricing context, its 1M-token context window, key benchmarks, and how to access it through the Gemini API and Google Cloud. You will also see what changed versus earlier Gemini Pro releases, what the official model card says about capabilities and safety, and how the release timeline fits into Google's broader Gemini 3 roadmap. By the end, you will have a clear mental model of where Gemini 3.1 Pro fits in the current LLM landscape and whether its performance, latency profile, and long-context features justify integrating it into your own stack.
Gemini 3.1 Pro Release and Availability
Google describes Gemini 3.1 Pro as "the next iteration in the Gemini 3 series" and, as of February 2026, its most advanced model for complex tasks in the Pro line. The launch blog frames it as the upgraded "core intelligence" behind the previously announced Gemini 3 Deep Think update, with a focus on stronger reasoning and more reliable performance on hard problems. From a practical standpoint, the Gemini 3.1 Pro release date corresponds to the public preview rollout described in that February 2026 model card.
In terms of channels, Gemini 3.1 Pro is already integrated across multiple Google surfaces. The model card lists distribution through the Gemini app, Google Cloud / Vertex AI, Google AI Studio, the Gemini API, Google Antigravity (Google's agentic development platform), and NotebookLM. The blog reinforces this by specifying that 3.1 Pro is:
- In preview for developers via the Gemini API in Google AI Studio, Gemini CLI, Google Antigravity, and Android Studio.
- Available for enterprises in Vertex AI and Gemini Enterprise.
- Rolling out for consumers in the Gemini app and NotebookLM for Pro and Ultra subscription tiers.
A subtle but important point is that Google explicitly positions this as a preview release to validate updates and refine agentic workflows before broad general availability. For teams planning adoption, this means Gemini 3.1 Pro release planning should account for potential API behavior changes, evolving evaluation numbers, and updated safety metrics as Google iterates. The unique angle here is that Google is clearly trying to ship frontier reasoning early, but with a controlled, preview-first rollout strategy that keeps them below internal "critical capability" thresholds monitored under their Frontier Safety Framework.
Gemini 3.1 Pro Context Window and Long-Context Use Cases
One of the most concrete technical specifications in the Gemini 3.1 Pro model card is the context window. Inputs can span up to 1 million tokens, with up to 64,000 tokens of output. That pushes Gemini 3.1 Pro into a class of models suitable for entire codebases, long research corpora, or deeply nested workflows where you want to keep many intermediate artifacts in memory.
The model card explicitly highlights applications that benefit from long context and multimodal understanding: agentic performance, advanced coding, algorithmic development, and tasks that need large-scale multimodal reasoning across text, audio, images, video, and full repositories. The Gemini 3 Pro page complements this by emphasizing that Gemini 3 models can synthesize information across text, images, video, audio, and code to help with learning, planning, and building.
A practical example from the Gemini 3.1 Pro blog illustrates the long-context, multimodal story: Gemini 3.1 Pro configures a live aerospace dashboard by wiring a public telemetry stream and visualizing the International Space Station's orbit, combining API reasoning, streaming data understanding, and interface design in one coherent output. In another example, it generates interactive 3D visual experiences with hand tracking and generative audio, again blending multiple modalities and complex code in a single session.
The unique insight here is that the Gemini 3.1 Pro context window is not only about fitting more tokens. The surrounding ecosystem matters. When you pair a 1M-token window with Google's agentic stack (Gemini API, Antigravity, and Vertex AI tools), you effectively get a system that can keep large task graphs and asset trees "in mind" while orchestrating multi-step workflows. For serious users, Gemini 3.1 Pro context window planning should consider how to partition long-running processes into reusable segments that still sit within that 1M-token budget.
Gemini 3.1 Pro Benchmarks and Reasoning Performance
Google positions Gemini 3.1 Pro as a step function improvement in reasoning relative to previous Pro models. The launch blog calls out ARC-AGI-2, a benchmark that stresses a model's ability to solve entirely new logic patterns. Gemini 3.1 Pro reaches a verified score of 77.1 percent, more than double the reasoning performance of Gemini 3 Pro on that test.
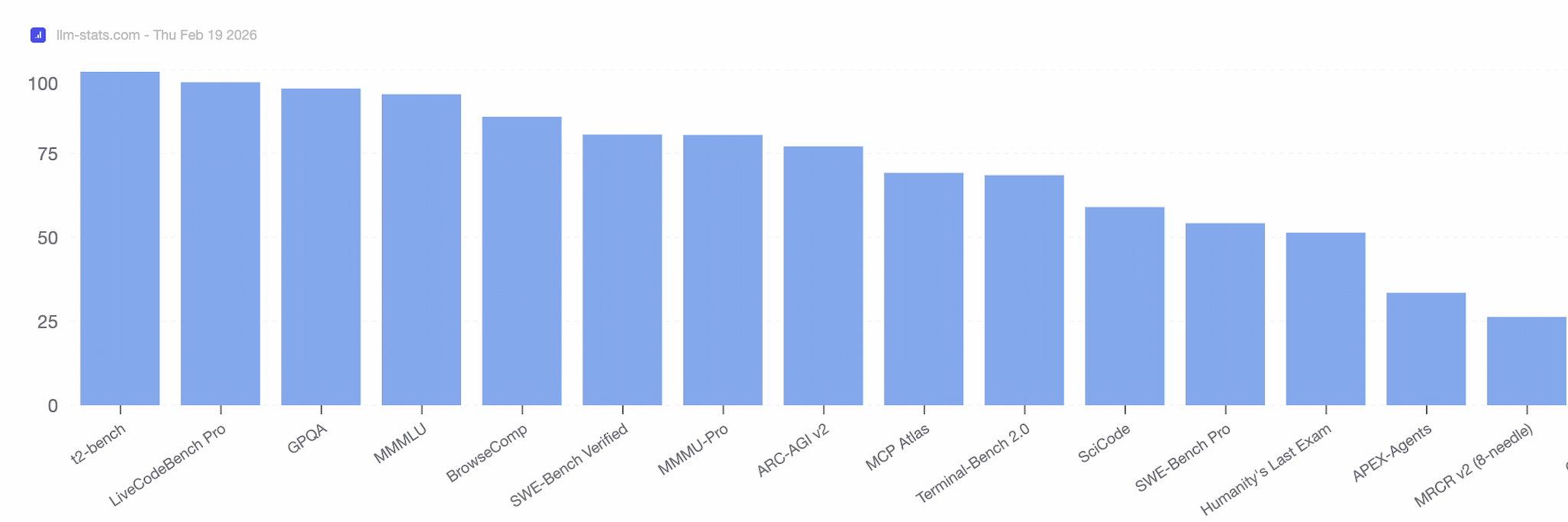
Gemini 3.1 Pro benchmark results across key evaluation datasets. Source: llm-stats.com
Beyond that headline number, the model card states that Gemini 3.1 Pro significantly outperforms Gemini 2.5 Pro across a range of benchmarks requiring enhanced reasoning and multimodal capabilities. It also links to a dedicated evaluations methodology page for Gemini 3.1 Pro at deepmind.google/models/evals-methodology/gemini-3-1-pro, which contains more granular benchmark breakdowns.
In the Frontier Safety Framework section, Google reports that Gemini 3.1 Pro, especially in Deep Think mode, shows clear gains on ML research benchmarks such as RE-Bench, achieving a human-normalized average score of 1.27 compared to Gemini 3 Pro's 1.04. On one challenge (optimizing an LLM fine-tuning script), the model cuts runtime from 300 seconds to 47 seconds versus a human reference solution of 94 seconds.
The interesting angle is that these benchmarks are not only about exam-style test suites. Google is using performance on real ML engineering workloads and reasoning about ML systems themselves as a signal of progress, while keeping Gemini 3.1 Pro below critical capability thresholds in areas like CBRN, cyber, and harmful manipulation. For practitioners, Gemini 3.1 Pro benchmarks should be interpreted as evidence of strong upstream reasoning capacity, especially on unfamiliar patterns and technical domains, rather than as marginal percentage bumps on standard leaderboards.
Safety, Tone, and Refusals
The model card also summarizes internal safety and tone evaluations. Relative to Gemini 3.0 Pro, Gemini 3.1 Pro improves slightly in automated text-to-text safety, multilingual safety, and the tone of refusals, while keeping unjustified refusals low. Losses on image-to-text safety are described as non-egregious and largely false positives, confirmed via manual review.
In the Frontier Safety Framework, Gemini 3.1 Pro remains below alert thresholds across CBRN, cyber, harmful manipulation, ML R&D, and misalignment critical capability levels, despite increased cyber and ML-R&D competence. That combination of higher capability with explicit controls is central to Google's positioning of the model as suitable for "real-world complexity" without crossing the internal lines that would trigger stricter deployment constraints. For anyone deploying Gemini 3.1 Pro in regulated domains, this safety-benchmark pairing is as important as raw performance metrics.
Gemini 3.1 Pro API Access, Latency, and Pricing Context
The Gemini 3.1 Pro model card states that the model is distributed via an API and that there is no required hardware or software beyond access to the Gemini API or Vertex AI. Documentation referenced includes the Gemini API Additional Terms of Service, Google Cloud Platform Terms of Service, and quickstarts for Gemini API in AI Studio and Vertex AI. This confirms that all Gemini 3.1 Pro pricing, latency, and quota behavior is mediated through those platforms rather than being published directly in the model card.

Gemini 3.1 Pro pricing, performance, and capabilities overview. Source: llm-stats.com
The Gemini 3.1 Pro blog clarifies the developer on-ramps: Gemini AI Studio for quick experimentation, Gemini CLI and Android Studio for integrated development, and Google Antigravity for agentic applications. For enterprises, Gemini 3.1 Pro is available through Vertex AI and Gemini Enterprise, which means billing, rate limits, and latency tuning align with standard Google Cloud practices.
The model card itself does not list numeric latency values or a detailed Gemini 3.1 Pro pricing table. Instead, it focuses on capabilities, safety, and evaluation. For up-to-date Gemini 3.1 Pro price and latency characteristics, developers should check:
- The Gemini API pricing and quotas page in Google AI Studio.
- The Vertex AI model pricing section in Google Cloud documentation for Pro-tier models.
- Gemini Enterprise billing details via Google Workspace or Cloud billing consoles.
The unique insight here is that Gemini 3.1 Pro latency and pricing should be evaluated in the context of its 1M-token context window and agentic capabilities. For some workloads, paying a higher per-token rate for a model that can keep more context and perform deeper reasoning can reduce total system cost by collapsing multi-call pipelines into fewer, more decisive requests. That tradeoff depends less on headline price per thousand tokens and more on how effectively you can exploit the Gemini 3.1 Pro API and its long-context behavior.
Quick Takeaways
- Most Advanced Pro-Tier Model: Gemini 3.1 Pro is Google's most advanced Pro-line model as of February 2026, with a focus on complex reasoning and multimodal tasks.
- 1M-Token Context Window: The model supports up to 1M tokens of input context and up to 64K tokens of output, enabling entire codebases and long documents in a single session.
- ARC-AGI-2 Performance: On ARC-AGI-2, Gemini 3.1 Pro achieves 77.1 percent, more than double Gemini 3 Pro's reasoning performance.
- Broad Availability: The model is available via the Gemini app, Gemini API, AI Studio, Vertex AI, Antigravity, and NotebookLM, primarily in preview for developers and enterprises.
- Significant Benchmark Gains: Gemini 3.1 Pro significantly outperforms Gemini 2.5 Pro on reasoning and multimodal benchmarks while remaining below internal critical capability thresholds in the Frontier Safety Framework.
- Pricing via Platform: Pricing and latency details are not embedded in the model card; they are managed through Gemini API and Vertex AI documentation and billing surfaces.
Conclusion
Gemini 3.1 Pro marks a meaningful escalation of Google's Pro-tier models, not just as a marginal upgrade but as a more capable baseline for hard reasoning problems, long-context workflows, and multimodal code-centric applications. With a 1M-token context window and strong performance on demanding benchmarks such as ARC-AGI-2 and ML-R&D suites like RE-Bench, it targets users who need a model that can operate over large, complex problem spaces rather than simple prompt-and-answer interactions.
From an integration perspective, the breadth of distribution is notable. Gemini 3.1 Pro is woven into the Gemini app, NotebookLM, Gemini API, AI Studio, Vertex AI, and Google Antigravity, so teams can move from experimentation to production without changing core models. At the same time, Google's Frontier Safety Framework shows that the model remains below critical capability thresholds in sensitive domains, which matters for organizations deploying in security- or compliance-constrained settings.
If you are evaluating Gemini 3.1 Pro for real workloads, the next step is to benchmark it on your own tasks through Google AI Studio or Vertex AI, paying attention to how its long-context and agentic strengths affect overall system complexity and cost. Used well, Gemini 3.1 Pro can replace brittle multi-model pipelines with a single, more capable engine that handles reasoning, tool use, and multimodal understanding in one place.
Questions
Frequently Asked Questions
Gemini 3.1 Pro is a natively multimodal reasoning model in the Gemini 3 series and, as of February 2026, Google's most advanced Pro-tier system for complex tasks. It builds on Gemini 3 Pro and can handle text, images, audio, video, and code with a long context window.
The model accepts inputs up to 1 million tokens and can generate outputs up to 64,000 tokens. This long context window is designed for use cases like full-repository code understanding, large document analysis, and multi-step agentic workflows.
On ARC-AGI-2, Gemini 3.1 Pro reaches a verified score of 77.1 percent, more than double Gemini 3 Pro's reasoning performance. The model card reports significant gains over Gemini 2.5 Pro across a range of reasoning and multimodal benchmarks and improved ML R&D performance on RE-Bench.
- Gemini 3.1 Pro is available through the Gemini app, Google Cloud / Vertex AI, Google AI Studio, the Gemini API, Google Antigravity, and NotebookLM. Developers typically start in AI Studio or Vertex AI, while end users see it through the Gemini app and NotebookLM.
- The official Gemini 3.1 Pro model card is published as a PDF titled "Gemini 3.1 Pro Model Card" and dated February 2026. For benchmark details and evaluation methodology, the card points to deepmind.google/models/evals-methodology/gemini-3-1-pro and related Gemini 3 Pro documentation.
Continue Reading