GPT-5.2: Complete Guide to Pricing, Context Window, Benchmarks, and API
A comprehensive look at OpenAI's GPT-5.2 -- the most capable model yet with 400K context window, 3 specialized variants (Instant, Thinking, Pro), 90%+ on ARC-AGI-1, pricing at $1.75/$14 per 1M tokens, and what it means for developers and enterprises.


Introduction: OpenAI's Most Capable Model Yet
The release of GPT-5.2 on December 11, 2025, marks OpenAI's most ambitious leap forward since GPT-4. Announced amid fierce competition with Google's Gemini 3 Pro (a rivalry that reportedly triggered a "Code Red" response within OpenAI), this release delivers on nearly every front that matters to developers and enterprises alike.
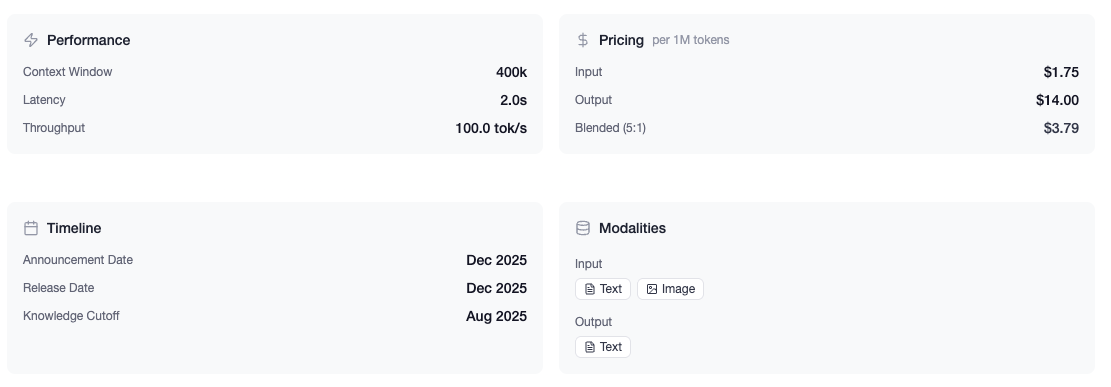
What makes GPT-5.2 stand apart isn't just incremental improvement. It's a model built around a 400,000-token context window, the ability to output up to 128,000 tokens in a single response, and three distinct variants tailored for different workloads: Instant, Thinking, and Pro. For the first time, OpenAI has crossed the 90% threshold on ARC-AGI-1, a benchmark designed to measure genuine reasoning ability, not pattern matching.
Whether you're researching GPT-5.2 pricing, evaluating the GPT-5.2 API for production use, or trying to understand how its benchmarks compare to Claude 4.5 Sonnet and Gemini 3 Pro, this guide covers everything: context window details, latency improvements, real-world applications, and the full technical breakdown.
At a Glance: GPT-5.2 Key Specs & Variants
| Spec | Value |
|---|---|
| Release Date | December 11, 2025 |
| Context Window | 400,000 tokens |
| Max Output | 128,000 tokens |
| Variants | Instant, Thinking, Pro |
| Latency | 18% faster than GPT-5 |
| Availability | OpenAI API, ChatGPT, Azure OpenAI |
Choosing the Right Variant
The three variants aren't just marketing tiers. They represent fundamentally different compute allocation strategies:
| Variant | Best For | Latency | Reasoning Depth | Cost |
|---|---|---|---|---|
| Instant | High-volume, latency-sensitive tasks | Fastest | Standard | Base rate |
| Thinking | Multi-step analysis, planning | Moderate | Configurable (Light->Heavy) | Base rate |
| Pro | Research, advanced math, complex coding | Slowest | Maximum | Base rate |
GPT-5.2 Instant optimizes for throughput. Use it for customer support, content generation, translation, and any task where you're processing thousands of requests and speed matters more than depth.
GPT-5.2 Thinking introduces a reasoning dial. The "thinking time" toggle (Light/Medium/Heavy) lets you trade latency for depth on a per-request basis. This is useful when some queries need quick answers and others need careful analysis. This is the workhorse for most production applications.
GPT-5.2 Pro allocates maximum compute to reasoning. On FrontierMath, it scores 40.3% versus GPT-5's 26.3%, a 53% relative improvement. Reserve this for tasks where accuracy justifies the latency cost: scientific research, mathematical proofs, complex debugging.
GPT-5.2 Context Window: What 400K Tokens Actually Gets You
The GPT-5.2 context window of 400,000 tokens is 3× larger than GPT-5's 128K. Here's what that means in practice:
| Content Type | Approximate Token Count | Fits in GPT-5.2? |
|---|---|---|
| Average novel (80,000 words) | ~100,000 tokens | ✓ Yes |
| Full codebase (medium startup) | ~200,000-400,000 tokens | ✓ Borderline |
| 10-K SEC filing (large company) | ~150,000 tokens | ✓ Yes |
| 500-page legal contract | ~180,000 tokens | ✓ Yes |
| Full conversation history (1 week heavy use) | ~50,000-100,000 tokens | ✓ Yes |
Context Window Comparison
| Model | Input Context | Max Output | Practical Limit* |
|---|---|---|---|
| GPT-5.2 | 400K | 128K | ~350K usable |
| Gemini 3 Pro | 1M | 65K | ~900K usable |
| Claude 4.5 Sonnet | 200K | 64K | ~180K usable |
| GPT-5 | 128K | 32K | ~100K usable |
*Practical limit accounts for system prompts, output buffer, and reliability degradation at edge of context.
The 128K output capacity deserves attention. Previous models capped at 32K-64K output, forcing workarounds for long-form generation. GPT-5.2 can produce book-chapter-length responses, complete API documentation, or exhaustive code refactors in a single call.
For tasks exceeding the context window, GPT-5.2 Thinking supports the new Responses/compact endpoint, which compresses prior context intelligently rather than truncating it.
Performance Benchmarks: GPT-5.2 vs. the Competition
View release blog by OpenAI ->
Coding: SWE-Bench Results
| Benchmark | GPT-5.2 | GPT-5 | Claude 4.5 Sonnet | Delta vs GPT-5 |
|---|---|---|---|---|
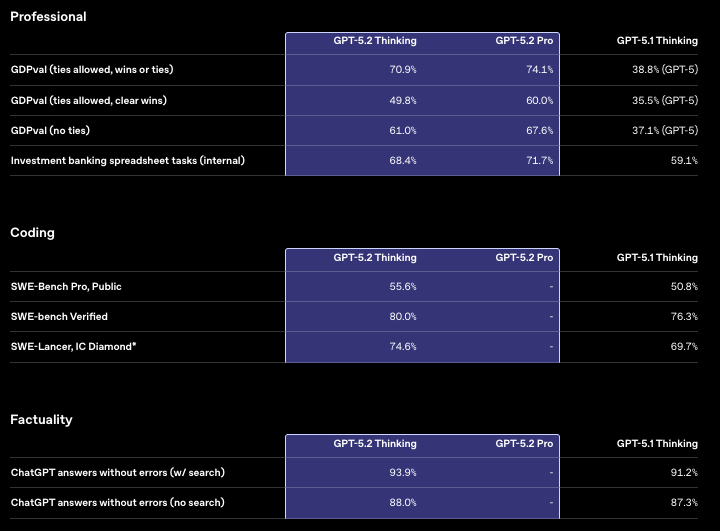
| SWE-Bench Verified | 80.0% | 76.3% | 76.5% | +3.7 pts |
| SWE-Bench Pro (Public) | 55.6% | 50.8% | -- | +4.8 pts |
The SWE-Bench Verified score of 80% means GPT-5.2 successfully resolves 4 out of 5 real GitHub issues when given the full repository context. These aren't toy problems. They're production codebases with complex dependencies, test suites, and multi-file changes.
Partner integrations with Windsurf, Warp, JetBrains, Augment Code, Cline, and Cognition report that GPT-5.2's expanded context window is the bigger practical gain. Many previously failing patches now succeed because the model can see the full codebase.
Reasoning: The ARC-AGI Milestone
| Benchmark | GPT-5.2 Pro | GPT-5.2 Thinking | o3-preview | GPT-5 |
|---|---|---|---|---|
| ARC-AGI-1 (Verified) | 90%+ | -- | 87% | ~75% |
| ARC-AGI-2 (Verified) | 54.2% | 52.9% | -- | -- |
Why ARC-AGI matters: Unlike benchmarks that can be gamed through memorization (MMLU, HellaSwag), ARC-AGI tests novel reasoning on problems the model has never seen. Each puzzle requires inferring abstract rules from a few examples, the kind of generalization that separates pattern matching from understanding.
Crossing 90% on ARC-AGI-1 is significant. A year ago, frontier models scored in the 30-40% range. The jump to 90%+ suggests genuine improvements in abstract reasoning, not just better training data coverage.
The cost story is equally notable: GPT-5.2 achieves 87% (o3-preview's score) at 390× lower cost. This makes reasoning-heavy workloads economically viable for the first time.
Knowledge Work: GDPval Results
| Metric | GPT-5.2 Thinking | GPT-5 | Improvement |
|---|---|---|---|
| Win/Tie vs Professionals | 70.9% | 38.8% | +32.1 pts |
| Occupations Tested | 44 | 44 | -- |
This is the most underrated result in the release. GDPval tests well-specified knowledge tasks: the kind of work that actually fills workdays: writing reports, analyzing spreadsheets, creating presentations, summarizing documents.
A 32-point jump means GPT-5.2 went from losing to professionals most of the time to winning or tying 7 out of 10 matchups. For enterprise buyers, this translates directly to productivity gains. OpenAI reports that heavy ChatGPT Enterprise users save 10+ hours per week. GPT-5.2 should expand both the user base and the savings.
Science & Math
| Benchmark | GPT-5.2 Pro | GPT-5 | Claude 4.5 Sonnet |
|---|---|---|---|
| GPQA Diamond | 93.2% | ~85% | 78.4% |
| FrontierMath (Tiers 1-3) | 40.3% | 26.3% | -- |
GPQA Diamond tests graduate-level physics, chemistry, and biology. These questions require both domain knowledge and multi-step reasoning. 93.2% approaches expert human performance.
FrontierMath is harder to contextualize. These are research-level math problems. A 40.3% score doesn't mean "fails 60% of the time." It means the model can contribute meaningfully to problems that challenge professional mathematicians. OpenAI's companion publication describes researchers using GPT-5.2 Pro for proof exploration, where the model suggests viable approaches that humans then verify and extend.
Vision & Multimodal
GPT-5.2 handles visual reasoning tasks that require integrating image content with domain knowledge:
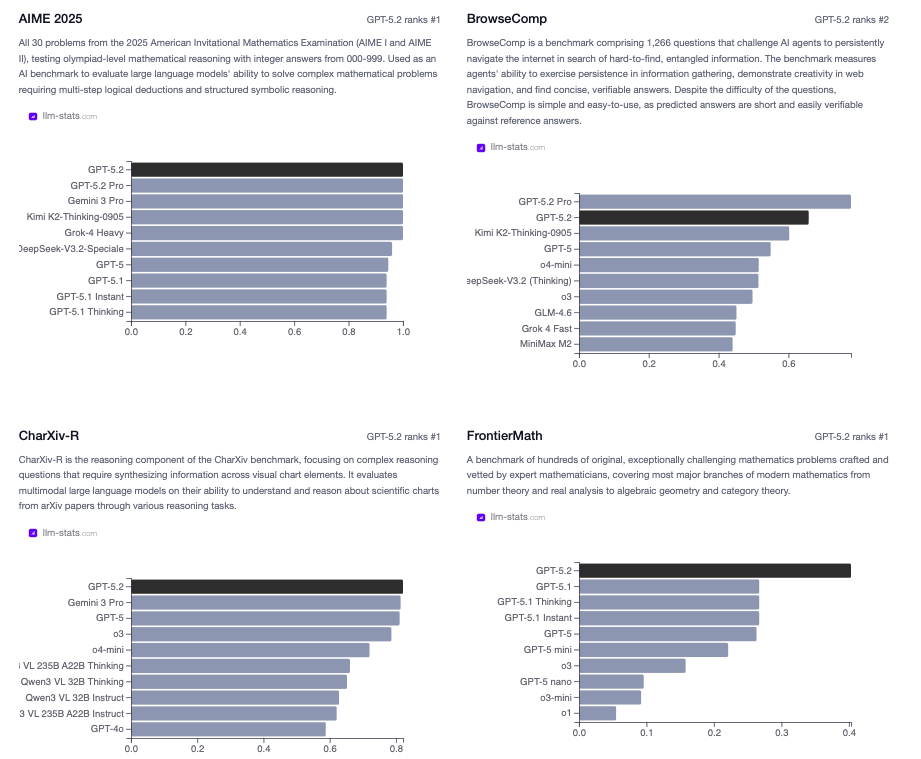
- CharXiv Reasoning: Interprets charts from scientific papers, answering questions that require reading values, understanding trends, and connecting to paper content
- ScreenSpot-Pro: Identifies UI elements in professional software screenshots. Useful for automation, documentation, and accessibility applications
Tool Use & Agents
For agentic applications, GPT-5.2 shows improvements on τ2-bench (customer support tasks with multi-turn tool use) and general structured output reliability. The combination of larger context, better reasoning, and improved tool calling makes GPT-5.2 a stronger foundation for agent systems than its predecessors.
GPT-5.2 Latency: The Numbers That Matter
| Task Type | GPT-5 | GPT-5.2 | Improvement |
|---|---|---|---|
| Time to first token (complex extraction) | 46s | 12s | 74% faster |
| Response time (analytical queries) | 19s | 7s | 63% faster |
| Overall latency | Baseline | -18% | -- |
The 18% headline understates the improvement for complex tasks. The optimization seems concentrated in the "thinking" phase. Queries that previously required long reasoning chains now resolve faster.
Infrastructure changes driving this:
- Specialized tensor cores for transformer operations
- Dynamic routing matching requests to optimal hardware
- Better parallelism across inference clusters
For production systems, the latency improvement changes what's viable. A 46-second wait breaks user flow; a 12-second wait is tolerable for complex tasks. This shifts the boundary of what you can build with synchronous API calls versus background processing.
GPT-5.2 API Pricing & Access

See pricing and available providers ->
API Pricing
| Tier | Input (per 1M) | Output (per 1M) | Effective Discount |
|---|---|---|---|
| Standard | $1.75 | $14.00 | -- |
| Cached Inputs | $0.175 | -- | 90% off input |
| Batch API | $0.875 | $7.00 | 50% off both |
Cost Per Task Estimates
| Task | Input Tokens | Output Tokens | Standard Cost | Batch Cost |
|---|---|---|---|---|
| Code review (single file) | ~2,000 | ~500 | $0.01 | $0.005 |
| Document summary (10 pages) | ~4,000 | ~1,000 | $0.02 | $0.01 |
| Full codebase analysis | ~200,000 | ~5,000 | $0.42 | $0.21 |
| Legal contract review | ~150,000 | ~10,000 | $0.40 | $0.20 |
The cached input pricing at $0.175/1M is the story for high-volume applications. If you're sending the same system prompt or context prefix repeatedly, you're paying 10× less for that portion. This makes RAG architectures and multi-turn conversations significantly cheaper.
GPT-5.2 vs Competitors: Price/Performance
| Model | Input/1M | Output/1M | SWE-Bench | Cost per 80% SWE-Bench task* |
|---|---|---|---|---|
| GPT-5.2 | $1.75 | $14.00 | 80.0% | ~$0.02 |
| Claude 4.5 Sonnet | $3.00 | $15.00 | 76.5% | ~$0.04 |
| Gemini 3 Pro | $1.25 | $5.00 | -- | -- |
| GPT-5 | $2.50 | $10.00 | 76.3% | ~$0.03 |
*Estimated based on typical code review token counts and success rates.
GPT-5.2 is cheaper than GPT-5 on input tokens ($1.75 vs $2.50) but more expensive on output ($14 vs $10). For input-heavy workloads (analysis, summarization), it's a price cut. For output-heavy workloads (generation), costs increase.
ChatGPT Subscription Access
| Tier | Monthly Cost | GPT-5.2 Instant | GPT-5.2 Thinking | GPT-5.2 Pro |
|---|---|---|---|---|
| Free | $0 | Limited | Limited | ✗ |
| Plus | $20 | ✓ Full | Rate limited | Limited |
| Pro | $200 | ✓ Full | ✓ Full | ✓ Full |
| Business | $25/user | ✓ Full | ✓ Full | ✓ Full |
When to Use GPT-5.2 (And When Not To)
GPT-5.2 Excels At
- Full-codebase operations: The 400K context means you can load entire repositories for refactoring, debugging, or documentation
- Long document analysis: Legal contracts, SEC filings, research papers. Analyze complete documents without chunking
- Complex reasoning tasks: Mathematical proofs, scientific analysis, multi-step planning
- High-stakes accuracy: When you need the most capable model and can tolerate latency
Consider Alternatives When
- Latency is critical: For real-time chat with sub-second response expectations, smaller models or GPT-5.2 Instant may be better
- Cost is primary concern: Gemini 3 Pro offers lower output pricing; open-source models offer significant savings for high-volume, lower-complexity tasks
- Context exceeds 400K: Gemini 3 Pro's 1M context window handles larger documents
- Simple tasks at scale: Using GPT-5.2 Pro for basic classification or extraction is overkill. Instant or smaller models deliver similar results at lower cost
Enterprise Validation
Partner deployments provide concrete evidence beyond benchmarks:
Box: Complex extraction tasks dropped from 46s to 12s, enabling real-time document intelligence that previously required background processing.
Harvey: The 400K context window allows analysis of complete case files (contracts, exhibits, correspondence) without chunking. This reduces hallucination from missing context and enables new legal research workflows.
Databricks, Hex, Triple Whale: Data analysis applications report that GPT-5.2's improved reasoning helps identify patterns across multiple data sources, the kind of insight that requires holding many facts in memory simultaneously.
The common thread: the combination of larger context and faster inference enables workflows that were previously impractical, not just faster versions of existing workflows.
Safety & Alignment
GPT-5.2 continues OpenAI's "safe completion" approach, which aims to find helpful responses within safety constraints rather than refusing aggressively.
Notable safety improvements:
- Better responses to prompts indicating self-harm risk
- Reduced false positive refusals on benign requests
- Age prediction model for automatic content filtering (under-18 protections)
- Improved resistance to jailbreak attempts
The system card (linked from OpenAI's release) provides detailed evaluation methodology.
Technical Architecture (What We Know)
OpenAI hasn't published a GPT-5.2 technical report. Based on observable behavior:
Inference optimization: The latency improvements suggest infrastructure changes rather than architectural changes: tensor core optimization, better routing, improved parallelism.
Reasoning mechanism: The "thinking time" toggle (Light/Medium/Heavy) implies variable compute allocation, likely similar to the chain-of-thought scaling seen in o3-preview.
Training: The focused improvements in math, science, and coding suggest targeted capability development, possibly through reinforcement learning on domain-specific tasks.
We'll update this section when OpenAI releases technical documentation.
Getting Started
API Integration
from openai import OpenAI
client = OpenAI()
# GPT-5.2 base
response = client.chat.completions.create(
model="gpt-5.2",
messages=[{"role": "user", "content": "Your prompt"}],
max_tokens=128000
)
# GPT-5.2 Thinking with reasoning effort
response = client.chat.completions.create(
model="gpt-5.2-thinking",
messages=[{"role": "user", "content": "Complex analysis task"}],
reasoning_effort="medium" # "light", "medium", or "heavy"
)
# GPT-5.2 Pro for maximum capability
response = client.chat.completions.create(
model="gpt-5.2-pro",
messages=[{"role": "user", "content": "Research-grade task"}]
)
Quick Reference: Model Selection
| If you need... | Use this variant |
|---|---|
| Fastest responses | Instant |
| Configurable depth | Thinking (adjust reasoning_effort) |
| Maximum accuracy | Pro |
| Cost optimization | Instant + Batch API |
| Long document processing | Any (all share 400K context) |
TL;DR
The headline numbers:
- 400K context (3× GPT-5): analyze full codebases and documents
- 128K max output: complete long-form generation in one call
- 90%+ on ARC-AGI-1: first model past this reasoning threshold
- 80% on SWE-Bench Verified: resolves 4/5 real GitHub issues
- 70.9% win rate vs professionals on GDPval, up from 38.8%
- 74% faster on complex tasks (46s -> 12s time to first token)
Pricing: $1.75/M input, $14/M output. Cached inputs at $0.175/M. Batch API at 50% off.
When to use it: Full-codebase analysis, long documents, complex reasoning, research tasks.
When to skip it: Simple high-volume tasks, extreme latency requirements, budget-constrained projects where accuracy trade-offs are acceptable.
Available now via OpenAI API, ChatGPT, and Azure OpenAI.
Explore model details on LLM Stats.
Questions
Frequently Asked Questions
GPT-5.2 is OpenAI's latest frontier model, featuring significant improvements in reasoning and mathematical capabilities over GPT-5. It achieves strong scores on GPQA Diamond and MATH benchmarks.
GPT-5.2 holds advantages in mathematical reasoning and tool integration, while Claude Opus 4.5 leads on coding benchmarks (SWE-bench) and safety evaluations. See our detailed comparison for the full benchmark breakdown.
Check the model page on LLM Stats for current pricing across all providers. GPT-5.2 maintains competitive pricing relative to other frontier models, with multiple providers offering different rate structures.
Continue Reading