Claude Opus 4.5 vs Gemini 3 Pro: Complete AI Model Comparison 2025
In-depth comparison of Claude Opus 4.5 and Gemini 3 Pro across benchmarks, pricing, context windows, multimodal capabilities, and real-world performance. Discover which AI model best fits your needs.


Two AI giants released flagship models within a week of each other in late November 2025. On November 18, Google launched Gemini 3 Pro with the industry's largest context window at 1 million tokens. Six days later, Anthropic responded with Claude Opus 4.5, the first model to break 80% on SWE-bench Verified, setting a new standard for AI-assisted coding.
These models represent fundamentally different design philosophies. Gemini 3 Pro prioritizes scale and multimodal versatility: a 1M token context window, native video/audio processing, and Deep Think parallel reasoning. Claude Opus 4.5 focuses on precision and persistence: Memory Tool for cross-session state, Context Editing for automatic conversation management, and unmatched coding accuracy.
This comparison examines where each model excels, where it falls short, and which one fits your specific use case.
At a Glance: Claude Opus 4.5 vs Gemini 3 Pro Key Specs
| Spec | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|
| Release Date | November 24, 2025 | November 18, 2025 |
| Context Window | 200,000 tokens | 1,000,000 tokens |
| Max Output | ~64,000 tokens | 64,000 tokens |
| Input Pricing | $5.00/M tokens | $2.00/M tokens |
| Output Pricing | $25.00/M tokens | $12.00/M tokens |
| Modalities | Text, images | Text, images, video, audio, PDFs |
| Key Feature | Memory Tool + best coding | 1M context + Deep Think reasoning |
| Providers | Claude API, AWS Bedrock, Google Vertex AI | Google AI Studio, Vertex AI, Gemini App |
| Key Strength | Coding accuracy, agent workflows | Context scale, scientific reasoning |
Claude Opus 4.5: The Persistent Coding Expert
Claude Opus 4.5 achieves an 80.9% score on SWE-bench Verified, the highest of any AI model. This benchmark tests real GitHub issues: understanding codebases, identifying bugs, and implementing multi-file fixes. For developers working on complex software projects, this represents a step change in AI assistance.
Three features define what makes Opus 4.5 different from other models.
Memory Tool
The Memory Tool (currently in beta) enables Claude to store and retrieve information beyond the context window by interacting with a client-side memory directory:
- Build knowledge bases over time across sessions
- Maintain project state between conversations
- Preserve extensive context through file-based storage
response = client.beta.messages.create(
betas=["context-management-2025-06-27"],
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[...],
tools=[{"type": "memory_20250818", "name": "memory"}]
)
For agents working on projects spanning days or weeks, this changes what's possible with AI assistance.
Context Editing
Context Editing (also in beta) automatically manages conversation context as it grows. When approaching token limits, it clears older tool calls while preserving recent, relevant information:
context_management={
"edits": [{
"type": "clear_tool_uses_20250919",
"trigger": {"type": "input_tokens", "value": 500},
"keep": {"type": "tool_uses", "value": 2},
"clear_at_least": {"type": "input_tokens", "value": 100}
}]
}
This is useful for long-running agent sessions where context accumulates over time.
Effort Parameter
The effort parameter trades off between speed and capability:
- Low effort: Fast responses, minimal tokens
- Medium effort: Matches Sonnet 4.5 performance while using 76% fewer tokens
- Maximum effort: Exceeds Sonnet 4.5 by 4.3 points using 48% fewer tokens
To read more about Claude Opus 4.5, check out our complete analysis.
Gemini 3 Pro: The Multimodal Powerhouse
Gemini 3 Pro's 1 million token context window is 5x larger than Claude Opus 4.5's capacity. This isn't just a bigger number. It enables fundamentally different workflows: processing entire codebases without chunking, analyzing hour-long videos, or synthesizing dozens of research papers in a single prompt.
Native Multimodal Architecture
Unlike systems that stitch together separate models for different modalities, Gemini 3 Pro processes text, images, video, audio, and PDFs through a unified architecture. This enables more coherent reasoning across data types. The model doesn't "translate" between modalities but understands them as integrated information streams.
Deep Think Parallel Reasoning
Deep Think evaluates multiple hypotheses simultaneously, synthesizing insights across parallel reasoning chains:
- 41.0% on Humanity's Last Exam (vs 37.5% base model)
- 45.1% on ARC-AGI-2 with code execution (vs 31.1% base)
Deep Think is currently exclusive to Google AI Ultra subscribers ($250/month).
Agentic Framework
Gemini 3 Pro includes Gemini Agent, a native agentic framework for autonomous task execution:
- Multi-Step Planning: Decomposes complex goals into actionable sequences
- Autonomous Execution: Carries out tasks with minimal human intervention
- Verification Loops: Self-checks results and iterates on failures
- Cross-Tool Orchestration: Coordinates actions across multiple services
Google Antigravity, launched alongside Gemini 3 Pro, showcases these capabilities in an AI-powered development environment with multi-agent orchestration.
To read more about Gemini 3 Pro, check out our complete analysis.
Performance Benchmarks: Claude Opus 4.5 vs Gemini 3 Pro
View full Claude Opus 4.5 vs Gemini 3 Pro comparison ->
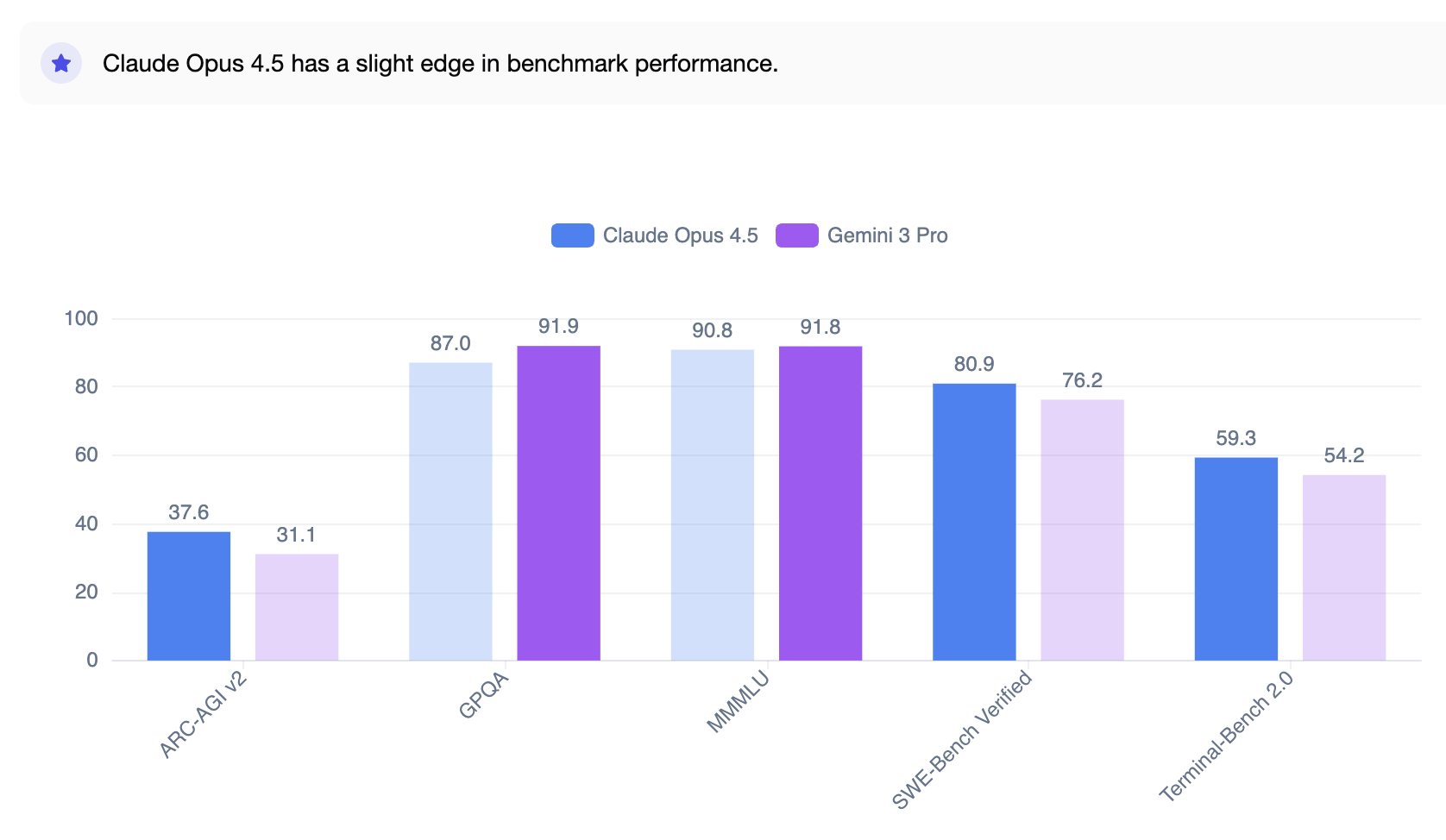
The benchmark comparison reveals distinct strengths. Claude Opus 4.5 leads in coding tasks, while Gemini 3 Pro dominates scientific reasoning and abstract problem-solving.
Coding Performance: Claude's Territory
| Benchmark | Claude Opus 4.5 | Gemini 3 Pro | Winner |
|---|---|---|---|
| SWE-Bench Verified | 80.9% | 76.2% | Claude (+4.7 pts) |
| Terminal-Bench 2.0 | 59.3% | 54.2% | Claude (+5.1 pts) |
| Aider Polyglot | 89.4% | -- | Claude |
| HumanEval | 84.9% | ~82% | Claude |
Claude Opus 4.5's 4.7-point lead on SWE-Bench Verified is significant. This benchmark tests real-world software engineering: understanding existing codebases, diagnosing bugs, and implementing fixes across multiple files. For teams building software, Claude resolves roughly 1 in 20 more issues correctly than Gemini.
The Terminal-Bench 2.0 gap (59.3% vs 54.2%) shows Claude's strength in command-line operations, terminal interactions, and system-level tasks.
Scientific Reasoning: Gemini's Domain
| Benchmark | Gemini 3 Pro | Claude Opus 4.5 | Winner |
|---|---|---|---|
| GPQA Diamond | 91.9% | 84% | Gemini (+7.9 pts) |
| Humanity's Last Exam | 37.5% | ~28% | Gemini (+9.5 pts) |
| ARC-AGI-2 | 31.1% | ~15% | Gemini (+16.1 pts) |
| ARC-AGI-2 (Deep Think) | 45.1% | -- | Gemini |
Gemini 3 Pro's scientific reasoning capabilities stand out. GPQA Diamond tests graduate-level physics, chemistry, and biology. Gemini's 91.9% score approaches expert human performance and significantly outpaces Claude's 84%.
The ARC-AGI-2 gap (31.1% vs ~15%) is the largest difference between these models. This benchmark tests novel abstract reasoning on problems the model has never seen. Gemini's ability to generalize from few examples to solve new puzzles demonstrates a meaningful capability advantage.
Mathematical Reasoning
| Benchmark | Gemini 3 Pro | Claude Opus 4.5 | Winner |
|---|---|---|---|
| AIME 2025 | 95.0% | ~94% | Gemini (+1 pt) |
| AIME 2025 (w/ code) | 100.0% | -- | Gemini |
| MathArena Apex | 23.4% | -- | Gemini |
Both models perform exceptionally on AIME 2025, with Gemini achieving a perfect 100% when allowed code execution. The MathArena Apex score (23.4%) demonstrates Gemini's capability on competition-level mathematics that push beyond standard benchmarks.
Multimodal Understanding
| Benchmark | Gemini 3 Pro | Claude Opus 4.5 | Winner |
|---|---|---|---|
| MMMU-Pro | 81.0% | ~75% | Gemini (+6 pts) |
| Video-MMMU | 87.6% | N/A | Gemini |
| OSWorld (computer use) | 52.4% | 66.3% | Claude (+13.9 pts) |
Gemini leads on multimodal benchmarks, but Claude's OSWorld score (66.3% vs 52.4%) reveals an interesting nuance: Claude is better at computer use tasks that involve screen interaction, clicking, and navigating desktop applications. Gemini excels at understanding multimedia content; Claude excels at taking actions on that content.
Key Considerations: Choosing Between Claude Opus 4.5 and Gemini 3 Pro
View full Claude Opus 4.5 vs Gemini 3 Pro comparison ->
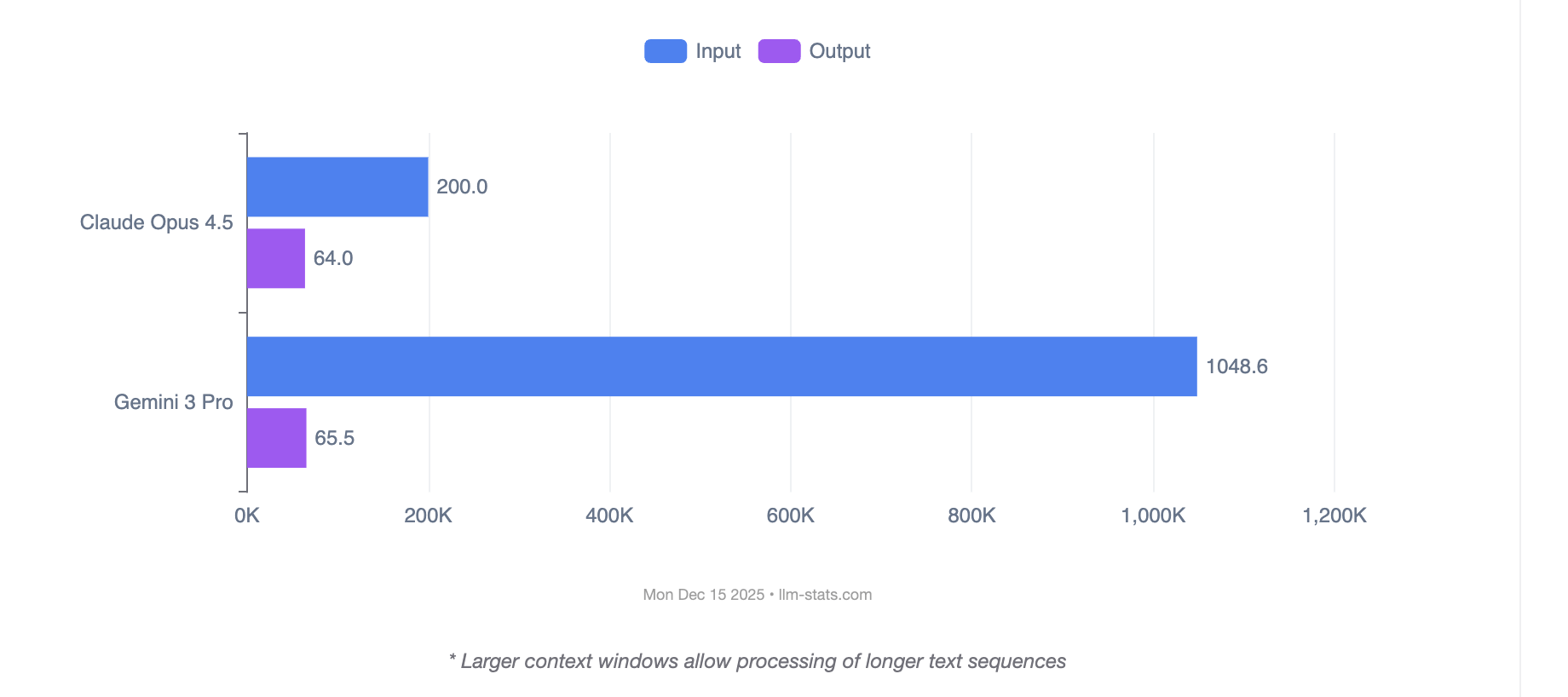
Context Window: The 5x Difference
The context window gap between these models is substantial. Gemini 3 Pro's 1 million tokens versus Claude Opus 4.5's 200,000 tokens determines which workflows are possible without workarounds.
| Content Type | Token Estimate | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|---|
| Average novel (80K words) | ~100K tokens | ✓ Yes | ✓ Yes |
| Full codebase (medium startup) | ~200-400K tokens | Borderline | ✓ Yes |
| Multiple SEC filings | ~500K tokens | ✗ No | ✓ Yes |
| Hour of video content | ~300K tokens | ✗ No | ✓ Yes |
| Complete legal case file | ~300K tokens | ✗ No | ✓ Yes |
| Research paper synthesis (50+ papers) | ~600K tokens | ✗ No | ✓ Yes |
Claude Opus 4.5's Memory Tool provides an alternative approach for some use cases, storing and retrieving information across sessions rather than holding everything in active context. This trades off immediate availability for persistence. You decide what the model remembers versus Gemini's approach where everything stays in the window.
Performance Priorities
Match your primary use case to model strengths:
- Choose Claude Opus 4.5 for: Complex coding tasks, terminal operations, long-running agent workflows, computer use automation, multi-cloud deployments
- Choose Gemini 3 Pro for: Scientific reasoning, large context analysis, video/audio processing, abstract problem-solving, cost-sensitive workloads
Speed and Latency
| Metric | Gemini 3 Pro | Claude Opus 4.5 |
|---|---|---|
| Time-to-First-Token | 420ms | 740ms |
| Tokens per second | 128 t/s | ~49 t/s |
| 1K Token Response | 2.9s | ~5.3s |
| Latency profile | Optimized for throughput | Optimized for accuracy |
Gemini 3 Pro's latency advantage stems from Google's TPU v5p optimization. For real-time applications, the ~300ms faster time-to-first-token and 2.6x higher throughput translate to noticeably more responsive interactions.
Claude's lower speed reflects its focus on accuracy over throughput. For tasks where getting the right answer matters more than getting a fast answer, the trade-off may be worthwhile.
Pricing Comparison: Claude Opus 4.5 vs Gemini 3 Pro
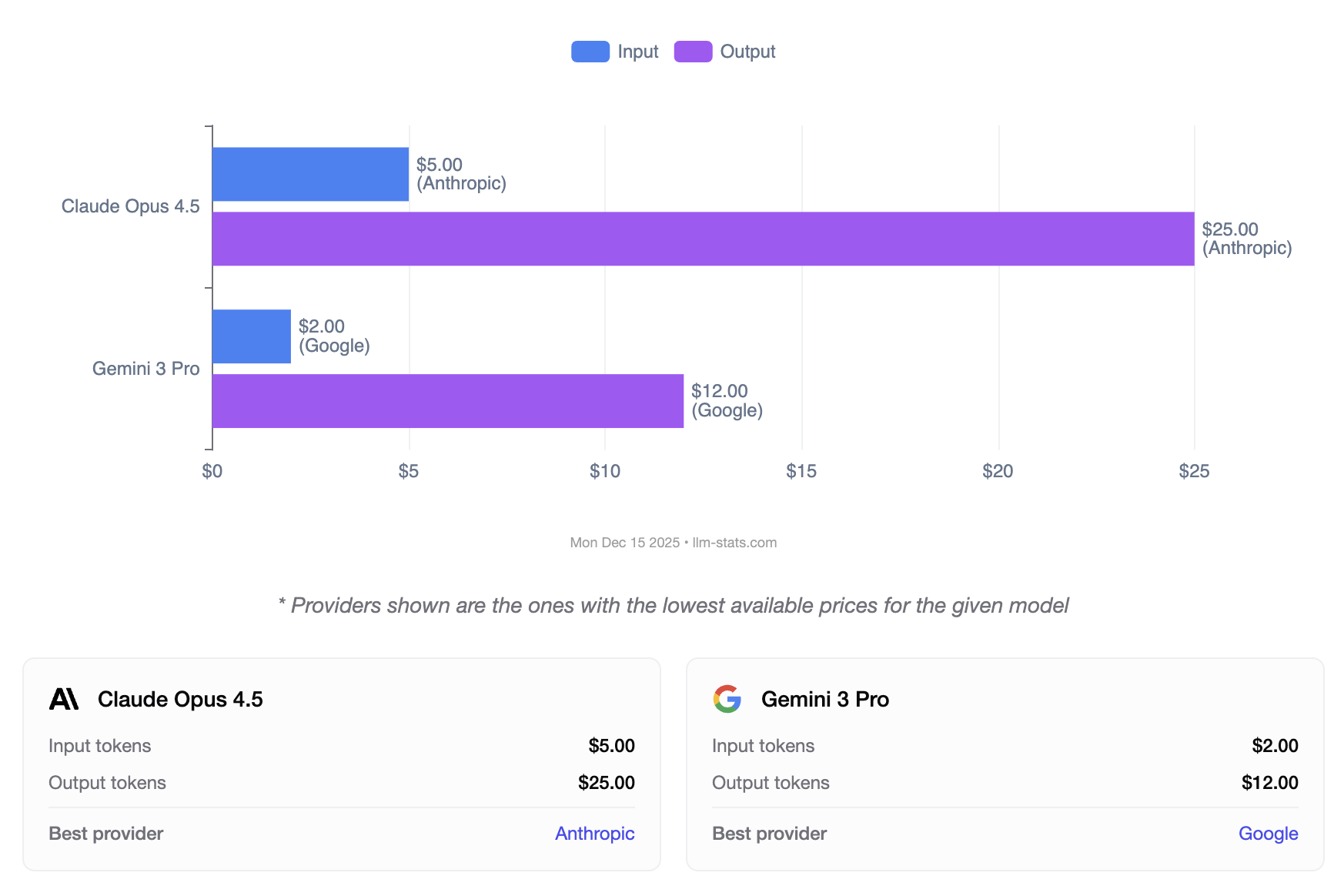
Gemini 3 Pro offers substantial cost savings. At $2.00 per million input tokens and $12.00 per million output tokens, it costs 60% less for input and 52% less for output compared to Claude Opus 4.5 at $5.00 and $25.00 respectively.
View detailed pricing breakdown ->
API Pricing Comparison
| Cost Type | Claude Opus 4.5 | Gemini 3 Pro | Difference |
|---|---|---|---|
| Input (per 1M) | $5.00 | $2.00 | Gemini 60% cheaper |
| Output (per 1M) | $25.00 | $12.00 | Gemini 52% cheaper |
| Extended Context (>200K) | N/A | $4.00 in / $18.00 out | Gemini only |
| Cached Inputs | $0.50/M (read) | $0.20-0.40/M | Gemini 20-60% cheaper |
| Batch API | 50% off | 50% off | Tie |
For high-volume applications, this pricing difference compounds quickly. Processing 10 million input tokens costs $50 with Claude versus $20 with Gemini.
Real-World Cost Scenarios
| Task | Claude Opus 4.5 | Gemini 3 Pro | Winner |
|---|---|---|---|
| Code review (single file, 5K tokens) | ~$0.03 | ~$0.01 | Gemini |
| 100K context analysis | ~$0.55 | ~$0.22 | Gemini |
| Full codebase analysis (300K) | ~$1.65 | ~$1.20 | Gemini |
| Video transcription + analysis | N/A | ~$0.50 | Gemini |
| Long-form generation (50K output) | ~$1.30 | ~$0.62 | Gemini |
| Multi-day agent workflow | Varies* | Higher base | Context-dependent* |
*Claude's Memory Tool can reduce costs for agent workflows by storing state externally rather than passing full context on each call.
When Claude's Premium Justifies the Cost
Despite higher pricing, Claude Opus 4.5 may offer better value for:
- Critical coding tasks: The 4.7-point SWE-Bench advantage means fewer errors and less human review
- Computer use automation: 13.9-point lead on OSWorld translates to higher success rates
- Regulated industries: AWS Bedrock integration provides enterprise security controls
- Agent continuity: Memory Tool enables workflows impossible with context-only approaches
Agentic Capabilities: Different Philosophies
Claude Opus 4.5: Persistent Memory Architecture
Claude's agentic approach centers on persistence and precision:
- Memory Tool: State preservation across sessions for multi-day projects
- Context Editing: Automatic context management as conversations grow
- Tool Selection Accuracy: Fewer errors during multi-step tool orchestration
- OSWorld Leadership: 66.3% accuracy on autonomous desktop operations
Internal evaluations show Claude's multi-agent coordination improved from 70.48% to 85.30% on deep-research benchmarks when combining tool use, context compaction, and memory.
Gemini 3 Pro: Scale-First Agent Design
Gemini's approach leverages massive context and native multimodal understanding:
- 1M Context: No need for external memory in most cases
- Gemini Agent: Native framework for autonomous multi-step execution
- Terminal-Bench 2.0: 54.2% on complex system operations
- Cross-Modal Reasoning: Agents can process video, audio, and documents natively
Google Antigravity demonstrates this in practice: an AI-powered IDE where multiple agents work on projects simultaneously, with browser integration for real-time testing.
Agent Use Case Recommendations
| Use Case | Recommended | Why |
|---|---|---|
| Multi-day research projects | Claude | Memory Tool persists state |
| Video/audio content workflows | Gemini | Native multimodal processing |
| Complex code refactoring | Claude | Higher SWE-Bench accuracy |
| Large document synthesis | Gemini | 1M context fits everything |
| Desktop automation | Claude | OSWorld leadership |
| Scientific analysis | Gemini | Superior reasoning scores |
Enterprise Deployments and Integration
Claude Opus 4.5 Enterprise Focus
Anthropic has prioritized regulated industries and enterprise security:
- First model to outperform humans on Anthropic's internal two-hour engineering assessments
- Accenture partnership: 30,000 employees being trained on Claude for financial services and healthcare
- Multi-cloud availability: Claude API, AWS Bedrock, and Google Vertex AI
- 66% price reduction from Opus 4.1 enabling broader enterprise adoption
Gemini 3 Pro Enterprise Integration
Google leverages its cloud infrastructure for enterprise deployment:
- Google Cloud integration: Native Vertex AI deployment with enterprise SLAs
- Google Workspace: Deep integration for productivity applications
- Context caching: Reduce costs for repeated analysis of the same documents
- Free tier: Google AI Studio enables evaluation before commitment
Industry Recommendations
| Industry | Recommended Model | Reasoning |
|---|---|---|
| Software Development | Claude Opus 4.5 | Higher coding accuracy |
| Media & Entertainment | Gemini 3 Pro | Video/audio processing |
| Legal | Gemini 3 Pro | Large document analysis |
| Healthcare | Both viable | Claude for coding, Gemini for research |
| Financial Services | Claude Opus 4.5 | Accenture partnership, Bedrock security |
| Research & Academia | Gemini 3 Pro | Scientific reasoning, paper synthesis |
| Customer Support | Gemini 3 Pro | Cost efficiency at scale |
Developer Experience: APIs and Integrations
API Integration Examples
Claude Opus 4.5:
import anthropic
client = anthropic.Anthropic()
# Standard request
response = client.messages.create(
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[{"role": "user", "content": "Your prompt here"}]
)
# With Memory Tool (beta)
response = client.beta.messages.create(
betas=["context-management-2025-06-27"],
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[{"role": "user", "content": "Your prompt here"}],
tools=[{"type": "memory_20250818", "name": "memory"}]
)
Gemini 3 Pro:
import google.generativeai as genai
genai.configure(api_key="YOUR_API_KEY")
model = genai.GenerativeModel("gemini-3-pro")
# Standard request
response = model.generate_content("Your prompt here")
# With video input
video_file = genai.upload_file("video.mp4")
response = model.generate_content([video_file, "Analyze this video"])
Feature Comparison
| Feature | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|
| Streaming | ✓ | ✓ |
| Function calling | ✓ | ✓ |
| Vision | ✓ | ✓ |
| Video processing | ✗ | ✓ |
| Audio processing | ✗ | ✓ |
| PDF analysis | ✓ (as images) | ✓ (native) |
| Memory/state | ✓ (Memory Tool beta) | ✗ (use context) |
| Context caching | ✓ | ✓ |
| Batch API | ✓ (50% off) | ✓ (50% off) |
Provider Availability
| Provider | Claude Opus 4.5 | Gemini 3 Pro |
|---|---|---|
| Native API | ✓ | ✓ |
| AWS Bedrock | ✓ | ✗ |
| Google Vertex AI | ✓ | ✓ |
| Google AI Studio | ✗ | ✓ (free tier) |
| Microsoft Azure | ✗ | ✗ |
Claude's presence on AWS Bedrock provides an option for organizations with AWS-centric infrastructure. Gemini's free tier through Google AI Studio lowers the barrier to experimentation.
The Future of AI: Contrasting Architectures
These models represent two distinct visions for AI development.
Claude Opus 4.5's persistence-first approach bets that AI assistants need memory and context management to handle real-world tasks. The Memory Tool enables workflows where the AI builds knowledge over weeks, not just within single sessions. This mirrors how human experts work: accumulating understanding over time.
Gemini 3 Pro's scale-first approach bets that bigger context windows solve the memory problem differently. With 1 million tokens, you can include everything relevant in a single prompt, eliminating the need for external memory systems. Combined with native multimodal processing, this enables workflows that treat text, images, video, and audio as unified information.
Both approaches have merit. Claude's architecture may prove more efficient for long-running projects where only specific information needs persistence. Gemini's architecture may prove more powerful for tasks requiring holistic understanding of massive datasets.
The competition between these philosophies will drive continued innovation in AI system design.
The Verdict: Specialists, Not Generalists
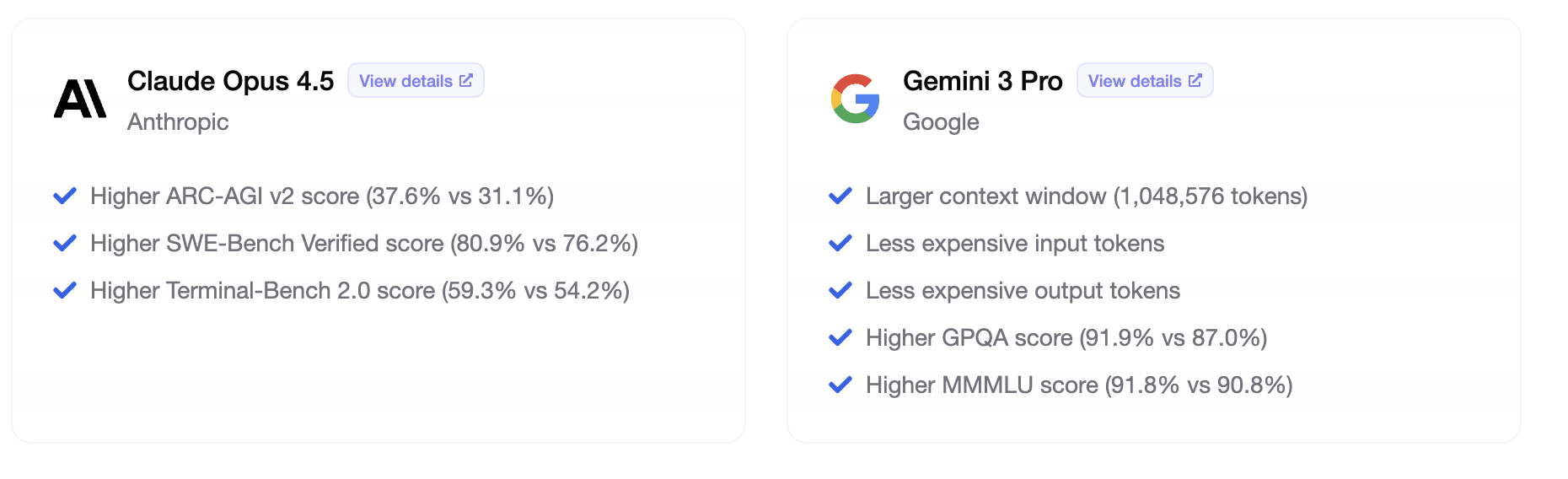
| Category | Winner | Margin |
|---|---|---|
| Coding (SWE-bench) | Claude Opus 4.5 | +4.7 pts (80.9% vs 76.2%) |
| Scientific Reasoning (GPQA) | Gemini 3 Pro | +7.9 pts (91.9% vs 84%) |
| Abstract Reasoning (ARC-AGI-2) | Gemini 3 Pro | +16.1 pts (31.1% vs ~15%) |
| Context Window | Gemini 3 Pro | 5x larger (1M vs 200K) |
| Processing Speed | Gemini 3 Pro | 2.6x faster |
| Pricing | Gemini 3 Pro | 52-60% cheaper |
| Computer Use | Claude Opus 4.5 | +13.9 pts (66.3% vs 52.4%) |
| Multimodal Input | Gemini 3 Pro | Video + audio support |
| Agent Memory | Claude Opus 4.5 | Unique Memory Tool |
| Enterprise Security | Claude Opus 4.5 | AWS Bedrock integration |
Claude Opus 4.5 and Gemini 3 Pro are specialists, not generalists. Claude excels at what developers need most: writing, understanding, and fixing code. Gemini excels at what researchers and analysts need: processing massive contexts, understanding multimedia, and reasoning about complex problems.
Your choice depends on your primary use case. Both models represent the current frontier of AI capability.
TL;DR
Claude Opus 4.5 (November 24, 2025):
- 200K context, Memory Tool for persistent state across sessions
- First to cross 80% on SWE-bench Verified (80.9%)
- OSWorld computer use: 66.3% (best in class)
- $5/M input, $25/M output
- Memory Tool + Context Editing for long-running agents
- Available on Claude API, AWS Bedrock, Google Vertex AI
- Best for: Complex coding, computer use, long-running agents, enterprise security
Gemini 3 Pro (November 18, 2025):
- 1M context window (5x larger), 64K max output
- GPQA Diamond: 91.9%, ARC-AGI-2: 31.1% (reasoning leader)
- Native video, audio, and PDF processing
- $2/M input, $12/M output (52-60% cheaper)
- Deep Think for complex reasoning ($250/month AI Ultra)
- Available on Google AI Studio (free tier), Vertex AI
- Best for: Large context analysis, scientific reasoning, multimodal tasks, cost efficiency
The Bottom Line: Claude Opus 4.5 for coding and computer use. Gemini 3 Pro for reasoning and scale. Or use both strategically based on task requirements.
For a full breakdown of performance and pricing, check out our complete comparison.
Questions
Frequently Asked Questions
Claude Opus 4.5 outperforms Gemini 3 Pro on coding and reasoning benchmarks, while Gemini 3 Pro leads in multimodal understanding and offers a 4x larger context window. The best choice depends on your specific use case.
Gemini 3 Pro has lower input token pricing, making it more cost-effective for applications that process large amounts of input data. Claude Opus 4.5 is more expensive per token but may require fewer tokens for complex reasoning tasks.
Gemini 3 Pro has a 1M token context window, significantly larger than Claude Opus 4.5's context window. For long-document processing, Gemini 3 Pro can handle entire books or large codebases in a single request.
Continue Reading