GPT-5.2 vs Claude Opus 4.5: Complete AI Model Comparison 2025
In-depth comparison of GPT-5.2 and Claude Opus 4.5 across benchmarks, pricing, context windows, agentic capabilities, and real-world performance. Discover which AI model best fits your needs.


The AI landscape shifted in late 2025. On November 24, Anthropic released Claude Opus 4.5, the first model to cross 80% on SWE-bench Verified, instantly becoming the benchmark leader for coding tasks. Less than three weeks later, on December 11, OpenAI responded with GPT-5.2, a model that shattered the 90% threshold on ARC-AGI-1, a benchmark designed to measure reasoning ability rather than pattern matching.
This isn't just another spec sheet comparison. GPT-5.2 and Claude Opus 4.5 represent different approaches to AI: OpenAI's self-verifying reasoner versus Anthropic's persistent agent. The question isn't which model is "better." It's which model is right for your specific workload. This guide examines architectural philosophies, benchmark performance, real-world deployments, and practical tradeoffs to help you make that decision.
At a Glance: GPT-5.2 vs Claude Opus 4.5 Key Specs
| Spec | GPT-5.2 | Claude Opus 4.5 |
|---|---|---|
| Release Date | December 11, 2025 | November 24, 2025 |
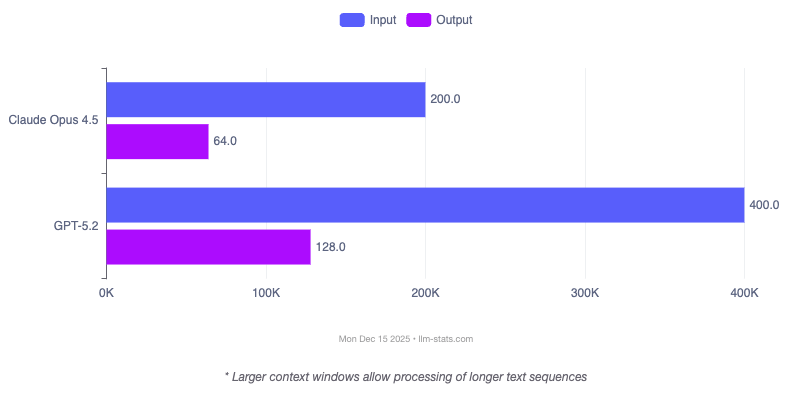
| Context Window | 400,000 tokens | 200,000 tokens |
| Max Output | 128,000 tokens | ~64,000 tokens |
| Input Pricing | $1.75/M tokens | $5.00/M tokens |
| Output Pricing | $14.00/M tokens | $25.00/M tokens |
| Variants | Instant, Thinking, Pro | Single model + Effort parameter |
| Providers | OpenAI API, Azure, ChatGPT | Claude API, AWS Bedrock, Google Vertex AI |
| Key Strength | Abstract reasoning, math | Coding accuracy, agent memory |
GPT-5.2: The Self-Verifying Reasoner
GPT-5.2 introduces a self-verification mechanism that changes how the model produces responses. Before finalizing any output, GPT-5.2 cross-references its responses against a distilled knowledge graph. This process adds less than 30 milliseconds of latency but reduces misinformation by approximately one-third in controlled trials.
GPT-5.2 also features a "temperature-consistency envelope" that ensures responses remain within a narrower variance band when temperature is below 0.7. For developers building deterministic pipelines in regulated industries like finance and healthcare, this improves output predictability.
The model's three-variant system (Instant, Thinking, Pro) reflects OpenAI's recognition that different tasks require different compute allocations:
| Variant | Best For | Reasoning Depth | Latency | Cost Impact |
|---|---|---|---|---|
| Instant | High-volume, latency-sensitive tasks | Minimal | Fastest | Base rate |
| Thinking | Balanced production workloads | Configurable (Light/Medium/Heavy) | Moderate | Base rate + thinking tokens |
| Pro | Research-grade problems | Maximum | Slowest | Highest (heavy thinking tokens) |
Critical detail: Thinking tokens are billed similarly to output tokens. When using GPT-5.2 Pro with heavy reasoning, your actual token count can be much higher than the visible output, sometimes 3-5x higher. Plan accordingly.
To read more about GPT-5.2, check out our complete analysis.
Claude Opus 4.5: The Persistent Agent
Claude Opus 4.5 takes a different approach, purpose-built for autonomous agent workflows that span hours, days, or weeks.
The Memory Tool (currently in beta) lets Claude store and retrieve information beyond the immediate context window by interacting with a client-side memory directory. This enables:
- Building knowledge bases over time across sessions
- Maintaining project state between conversations
- Preserving extensive context through file-based storage
response = client.beta.messages.create(
betas=["context-management-2025-06-27"],
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[...],
tools=[{"type": "memory_20250818", "name": "memory"}]
)
Context Editing (also in beta) automatically manages conversation context as it grows. When approaching token limits, it clears older tool calls while keeping recent, relevant information. This is useful for long-running agent sessions where context accumulates over time.
The Effort parameter offers control similar to GPT-5.2's variants but within a single model:
- Low effort: Fast responses, minimal tokens
- Medium effort: Matches Sonnet 4.5 performance while using 76% fewer tokens
- Maximum effort: Exceeds Sonnet 4.5 by 4.3 points using 48% fewer tokens
Internal evaluations show Claude Opus 4.5's multi-agent coordination improved from 70.48% to 85.30% on deep-research benchmarks when combining tool use, context compaction, and memory.
To read more about Claude Opus 4.5, check out our complete analysis.
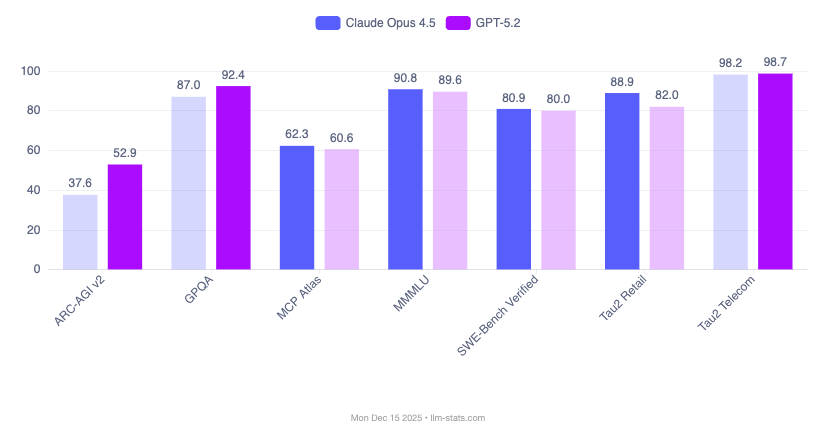
Performance Benchmarks: GPT-5.2 vs Claude Opus 4.5
View full GPT-5.2 vs Claude Opus 4.5 comparison ->
The performance comparison reveals distinct strengths for each model. Claude Opus 4.5 dominates in coding and tool use scenarios, while GPT-5.2 leads in abstract reasoning and mathematics.
Coding Performance: The Closest Race
| Benchmark | GPT-5.2 | Claude Opus 4.5 | Winner |
|---|---|---|---|
| SWE-Bench Verified | 80.0% | 80.9% | Claude (+0.9 pts) |
| Terminal-Bench 2.0 | 47.6% | 59.3% | Claude (+11.7 pts) |
| Aider Polyglot | -- | 89.4% | Claude |
| HumanEval | ~85% | 84.9% | Tie |
The SWE-Bench Verified score of 80.9% means Claude Opus 4.5 successfully resolves 4 out of 5 real GitHub issues when given the full repository context. These aren't toy problems. They're production codebases with complex dependencies, test suites, and multi-file changes.
Claude leads on coding, especially command-line and terminal operations where the gap widens to nearly 12 percentage points. If your primary use case is complex code generation and debugging, Claude Opus 4.5 holds the edge.
Abstract Reasoning: The Largest Gap
| Benchmark | GPT-5.2 Pro | Claude Opus 4.5 | Winner |
|---|---|---|---|
| ARC-AGI-1 | 90.5% | ~65% | GPT (+25 pts) |
| ARC-AGI-2 | 54.2% | 37.6% | GPT (+16.6 pts) |
Why ARC-AGI matters: Unlike benchmarks that can be gamed through memorization (MMLU, HellaSwag), ARC-AGI tests reasoning on problems the model has never seen. Each puzzle requires inferring abstract rules from a few examples, the kind of generalization that separates pattern matching from understanding.
A year ago, frontier models scored in the 30-40% range on ARC-AGI-1. GPT-5.2 Pro crossing 90% represents a major capability leap in abstract reasoning. The ARC-AGI-2 gap (54.2% vs 37.6%) is telling: for applications requiring novel reasoning, GPT-5.2's advantage is substantial.
Mathematical Reasoning
| Benchmark | GPT-5.2 | Claude Opus 4.5 | Winner |
|---|---|---|---|
| AIME 2025 | 100% | ~94% | GPT (+6 pts) |
| FrontierMath (Tiers 1-3) | 40.3% | -- | GPT |
| GPQA Diamond | 93.2% | 84% | GPT (+9.2 pts) |
GPT-5.2's perfect 100% score on AIME 2025 is historic: the first time any major model has achieved this on competition-level mathematics. GPQA Diamond tests graduate-level physics, chemistry, and biology, where GPT-5.2's 93.2% approaches expert human performance.
The 40.3% on FrontierMath deserves attention. These are research-level math problems. A score in this range means GPT-5.2 Pro can contribute to problems that challenge professional mathematicians, suggesting viable proof approaches that humans then verify and extend.
Professional Work (GDPval)
| Metric | GPT-5.2 Thinking | GPT-5 | Improvement |
|---|---|---|---|
| Win/Tie vs Professionals | 70.9% | 38.8% | +32.1 pts |
| Occupations Tested | 44 | 44 | -- |
This 32-point jump means GPT-5.2 went from losing to professionals most of the time to winning or tying 7 out of 10 matchups on tasks that actually fill workdays: writing reports, analyzing spreadsheets, creating presentations, summarizing documents. For enterprise buyers, this translates directly to productivity gains.
Key Considerations: Choosing Between GPT-5.2 and Claude Opus 4.5
View full GPT-5.2 vs Claude Opus 4.5 comparison ->
Context Window Requirements
Context requirements play a role in model selection. GPT-5.2's 400,000-token capacity provides advantages for applications processing extensive documents or maintaining long conversational threads. Claude Opus 4.5's 200K token limit may require document chunking strategies for very large inputs.
| Content Type | Token Estimate | GPT-5.2 | Claude Opus 4.5 |
|---|---|---|---|
| Average novel (80K words) | ~100K tokens | ✓ Yes | ✓ Yes |
| Full codebase (medium startup) | ~200-400K tokens | ✓ Yes | Borderline |
| Multiple SEC filings | ~500K tokens | ✓ Yes | ✗ No |
| Week of conversation history | ~50-100K tokens | ✓ Yes | ✓ Yes |
| Complete case file (legal) | ~300K tokens | ✓ Yes | ✗ No |
Claude Opus 4.5's Memory Tool effectively extends context infinitely for specific use cases. The trade-off is explicit memory management: you decide what persists versus GPT-5.2's implicit large context where everything stays in the window.
Performance Priorities
Performance priorities should align with model strengths:
- Choose GPT-5.2 for: Abstract reasoning, mathematical proofs, large context analysis, speed-critical applications, cost-sensitive high-volume workloads
- Choose Claude Opus 4.5 for: Complex coding tasks, terminal operations, long-running agent workflows, multi-cloud deployments
Speed and Latency
| Metric | GPT-5.2 | Claude Opus 4.5 |
|---|---|---|
| Tokens per second | 187 t/s | ~49 t/s |
| Speed advantage | 3.8x faster | Baseline |
| Time to first token (complex) | 12s | 2-4s typical |
| Latency profile | Optimized for throughput | Optimized for consistency |
GPT-5.2's processing speed advantage is significant for high-volume applications. The 3.8x faster token generation means real-time applications feel responsive where Claude might lag.
GPT-5.2's three variants let you trade latency for depth on a per-request basis. Some queries need quick answers, others need careful analysis. This flexibility works well for production applications.
Claude's effort parameter offers similar control within a single model, but the tuning is different: you're adjusting how much compute Claude allocates to each response rather than selecting different model weights.
Pricing Comparison: GPT-5.2 vs Claude Opus 4.5
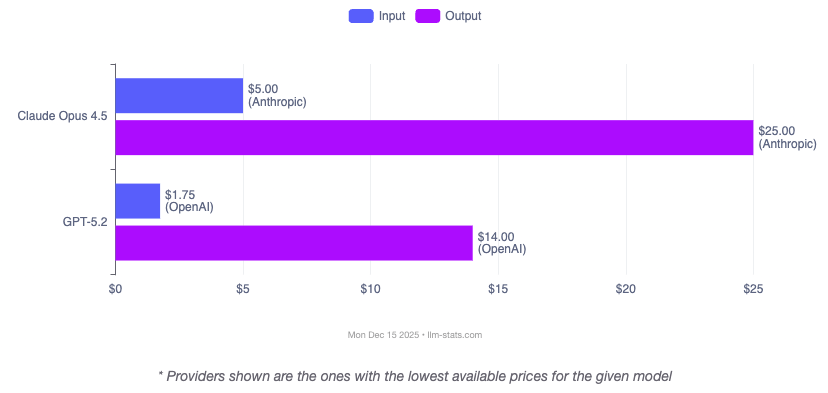
The pricing difference between these models is substantial. GPT-5.2 costs $1.75 per million input tokens and $14.00 per million output tokens, making it 65% cheaper for input and 44% cheaper for output compared to Claude Opus 4.5 at $5.00 and $25.00 respectively.
View detailed pricing breakdown ->
API Pricing Comparison
| Cost Type | GPT-5.2 | Claude Opus 4.5 | Difference |
|---|---|---|---|
| Input (per 1M) | $1.75 | $5.00 | GPT 65% cheaper |
| Output (per 1M) | $14.00 | $25.00 | GPT 44% cheaper |
| Cached Inputs | $0.175/M | $0.50/M (read) | GPT 65% cheaper |
| Batch API | 50% off | 50% off | Tie |
This cost advantage is significant for high-volume applications like API integrations, customer support automation, and content generation platforms. However, Claude Opus 4.5 may justify its premium through superior coding performance and the Memory Tool for long-running agents. Consider total cost of ownership beyond raw token pricing.
The Hidden Cost: Thinking Tokens
Critical for GPT-5.2 users: Thinking tokens (in Thinking and Pro modes) are billed as output tokens. A complex reasoning task might show 1,000 output tokens but actually consume 5,000+ tokens including hidden reasoning. Monitor your actual usage versus visible output.
Real-World Cost Scenarios
| Task | GPT-5.2 | Claude Opus 4.5 | Winner |
|---|---|---|---|
| Code review (single file) | ~$0.01 | ~$0.02 | GPT |
| 100K context analysis | ~$0.21 | ~$0.55 | GPT |
| Full codebase refactor | ~$0.45 | ~$1.10 | GPT |
| Heavy reasoning (Pro mode) | $2-5+ | ~$1.50 | Claude* |
| Long-form generation (50K output) | ~$0.75 | ~$1.30 | GPT |
*Claude wins on heavy reasoning only if GPT Pro's hidden thinking tokens are high.
Agentic Capabilities: Building Autonomous Systems
Claude Opus 4.5: Purpose-Built for Agents
Claude Opus 4.5 was designed with autonomous agents in mind:
- Memory Tool: Persistent state across sessions, so agents can remember what they learned yesterday
- Context Editing: Automatic context management as conversations grow
- Multi-agent coordination: 85.30% on deep-research benchmarks
- Tool selection accuracy: Fewer errors and reduced backtracking during tool invocation
Anthropic's partnership with Accenture to train 30,000 employees on Claude models (their largest deployment to date) focuses on integrating AI agents into workflows within regulated industries.
GPT-5.2: Structured Workflow Automation
GPT-5.2 approaches agents differently:
- Three variants: Different components of your agent can use different compute profiles
- Context-Free Grammars (CFGs): Strict output format guarantees via Lark grammars
- 400K context: Eliminates the need for external memory systems in most cases
- Self-verification: Reduces hallucinations in multi-step agent chains
The Verdict on Agents
| Use Case | Recommended | Why |
|---|---|---|
| Multi-day research projects | Claude | Memory Tool persists state |
| High-volume parallel tasks | GPT-5.2 | Faster processing, larger context |
| Complex tool orchestration | Claude | Better tool selection accuracy |
| Strict output format needs | GPT-5.2 | CFG support guarantees format |
| Long-horizon planning | GPT-5.2 | Superior reasoning (ARC-AGI) |
| Iterative code development | Claude | Higher coding accuracy |
Enterprise Deployments: Real-World Evidence
GPT-5.2 Enterprise Results
OpenAI's partner deployments provide concrete evidence:
- Box: Complex extraction tasks dropped from 46s to 12s (74% faster), enabling real-time document intelligence
- Harvey: Legal research with 400K context for complete case files without chunking, reducing hallucination from missing context
- Databricks, Hex, Triple Whale: Pattern identification across multiple data sources, enabling autonomous analytical workflows
- ChatGPT Enterprise: Heavy users report saving 10+ hours weekly, with average users saving 40-60 minutes daily
Companies like Notion, Shopify, and Zoom have observed GPT-5.2's strong performance in long-horizon reasoning and tool-calling, which is useful for complex business applications.
Claude Opus 4.5 Enterprise Results
Anthropic has focused on regulated industries and enterprise security:
- First model to outperform humans on Anthropic's internal two-hour engineering assessments
- Accenture partnership: 30,000 employees being trained on Claude models for financial services and healthcare
- Microsoft integration: Available in Microsoft Foundry and Microsoft 365 Copilot
- OSWorld computer use: 66.3% accuracy on autonomous desktop operations
- 66% price reduction from Opus 4.1 enabling broader enterprise adoption
Industry-Specific Recommendations
| Industry | Recommended Model | Reasoning |
|---|---|---|
| Financial Services | GPT-5.2 | Deterministic outputs, compliance |
| Legal | Both viable | GPT for context size, Claude for coding |
| Software Development | Claude Opus 4.5 | Slightly higher coding accuracy |
| Research/Science | GPT-5.2 | Superior reasoning and math |
| Healthcare | Claude Opus 4.5 | Bedrock availability, compliance |
| Data Analytics | GPT-5.2 | Pattern identification, large context |
Developer Experience: APIs and Integrations
Structured Outputs
| Feature | GPT-5.2 | Claude Opus 4.5 |
|---|---|---|
| JSON Schema adherence | Guaranteed | Strong |
| Context-Free Grammars | ✓ (Lark grammars) | ✗ |
| Pydantic/Zod integration | Limited | ✓ Enhanced |
| Multi-agent standardization | Manual | ✓ Native |
GPT-5.2's CFG support is valuable for database entry from unstructured inputs, agentic workflows requiring precise output formats, and integration with legacy systems expecting specific formats.
API Integration Examples
GPT-5.2:
from openai import OpenAI
client = OpenAI()
# GPT-5.2 Thinking with reasoning effort
response = client.chat.completions.create(
model="gpt-5.2-thinking",
messages=[{"role": "user", "content": "Complex analysis task"}],
reasoning_effort="medium" # "light", "medium", or "heavy"
)
Claude Opus 4.5:
import anthropic
client = anthropic.Anthropic()
# Claude Opus 4.5 with Memory Tool
response = client.beta.messages.create(
betas=["context-management-2025-06-27"],
model="claude-opus-4-5-20251101",
max_tokens=4096,
messages=[{"role": "user", "content": "Your prompt here"}],
tools=[{"type": "memory_20250818", "name": "memory"}]
)
Provider Availability
| Provider | GPT-5.2 | Claude Opus 4.5 |
|---|---|---|
| Native API | ✓ | ✓ |
| Azure OpenAI | ✓ | ✗ |
| AWS Bedrock | ✗ | ✓ |
| Google Vertex AI | ✗ | ✓ |
| Microsoft Foundry | ✓ | ✓ |
The Future of AI: GPT-5.2 vs Claude Opus 4.5 Architectures
These models represent two compelling visions for AI development. GPT-5.2's self-verification approach and three-variant system empowers developers with direct control over compute allocation, leading to more predictable resource utilization and transparent AI interactions.
Claude Opus 4.5's Memory Tool and Context Editing promises persistent AI interactions where agents can build knowledge over time. This approach may prove more effective for autonomous workflows and long-running tasks.
Both architectures offer compelling advantages, and their success will depend on specific use cases and user preferences. The competition between these approaches will drive continued innovation in AI system design.

The Verdict: Complementary Champions
| Category | Winner | Margin |
|---|---|---|
| Coding (SWE-bench) | Claude Opus 4.5 | +0.9 pts |
| Abstract Reasoning (ARC-AGI-2) | GPT-5.2 | +16.6 pts |
| Math (AIME 2025) | GPT-5.2 | +6 pts (100% vs 94%) |
| Context Window | GPT-5.2 | 2x larger (400K vs 200K) |
| Processing Speed | GPT-5.2 | 3.8x faster |
| Pricing | GPT-5.2 | 44-65% cheaper |
| Agentic Memory | Claude Opus 4.5 | Unique feature |
| Terminal Operations | Claude Opus 4.5 | +11.7 pts |
| Multi-Cloud Availability | Claude Opus 4.5 | Bedrock + Vertex |
GPT-5.2 and Claude Opus 4.5 represent the current pinnacle of AI development, each offering unique strengths suited to different applications. GPT-5.2 leads in reasoning, mathematics, speed, and cost efficiency, while Claude Opus 4.5 excels in coding accuracy, agentic workflows, and multi-cloud deployment. Your choice between them should align with your specific performance requirements, safety needs, and implementation timeline.
TL;DR
GPT-5.2 (December 11, 2025):
- 400K context window, 128K max output
- First model to hit 100% AIME 2025, 90%+ ARC-AGI-1
- 3.8x faster processing than Claude (187 vs 49 t/s)
- $1.75/M input, $14/M output (44-65% cheaper)
- Three variants (Instant/Thinking/Pro) for different compute needs
- Self-verification reduces hallucinations by ~33%
- Best for: Reasoning, math, large context, speed, cost efficiency
Claude Opus 4.5 (November 24, 2025):
- 200K context, Memory Tool for persistent state across sessions
- First to cross 80% on SWE-bench Verified (80.9%)
- Outperformed humans on engineering assessments
- $5/M input, $25/M output (66% cheaper than Opus 4.1)
- Memory Tool + Context Editing for long-running agent workflows
- Available on AWS Bedrock and Google Vertex AI
- Best for: Complex coding, long-running agents, multi-cloud deployment
The Bottom Line: GPT-5.2 for reasoning and scale, Claude Opus 4.5 for coding and agents. Or use both strategically for the best results.
For a full breakdown of performance and pricing, check out our complete comparison.
Questions
Frequently Asked Questions
Claude Opus 4.5 outperforms GPT-5.2 on SWE-bench Verified, the most widely cited real-world coding benchmark. For code generation, debugging, and software engineering tasks, Claude Opus 4.5 is generally the stronger choice.
GPT-5.2 holds a slight edge on mathematical reasoning benchmarks like MATH and competition-level problems. For math-heavy applications, GPT-5.2 may be the better choice.
Pricing varies by provider and usage pattern. Compare current pricing on each model's page on LLM Stats. Consider both per-token pricing and the number of tokens each model typically uses for your tasks — a model with higher per-token pricing may cost less overall if it solves problems in fewer tokens.
Continue Reading